字节跳动的前端工程化实践
受邀参加 2023 51CTO 举办的『WOT全球技术创新大会』
分享会背景
- 受邀参加 2023 51CTO 举办的『WOT全球技术创新大会』
- 字节跳动的前端工程化实践,大幅提高巨型应用构建和维护效益-51CTO.COM
本主题简介


PPT 正文


- 大家早上好,我叫林宜丙,今天带来的分享主题是『字节跳动的前端工程化实践』。

- 简单介绍下我自己,我是一名来 Web Infra 部门的前端架构工程师,拥有多年前端工程化的经验,致力于帮助前端工程师更好地管理和治理工程;目前负责工程治理方向的方案设计和落地工作。

- 今天的分享包括以下四个部分
- 首先分析『当下前端开发领域的趋势』,并引出字节跳动前端开发所面临的新挑战;
- 其次分享我们目前通过哪些实践来应对这些新挑战;
- 接着分享自研的方案在字节跳动的整体落地情况;
- 最后总结和展望前端工程化的发展规律;
- OK,在分享之前,我们先来看看『什么是前端工程化?』
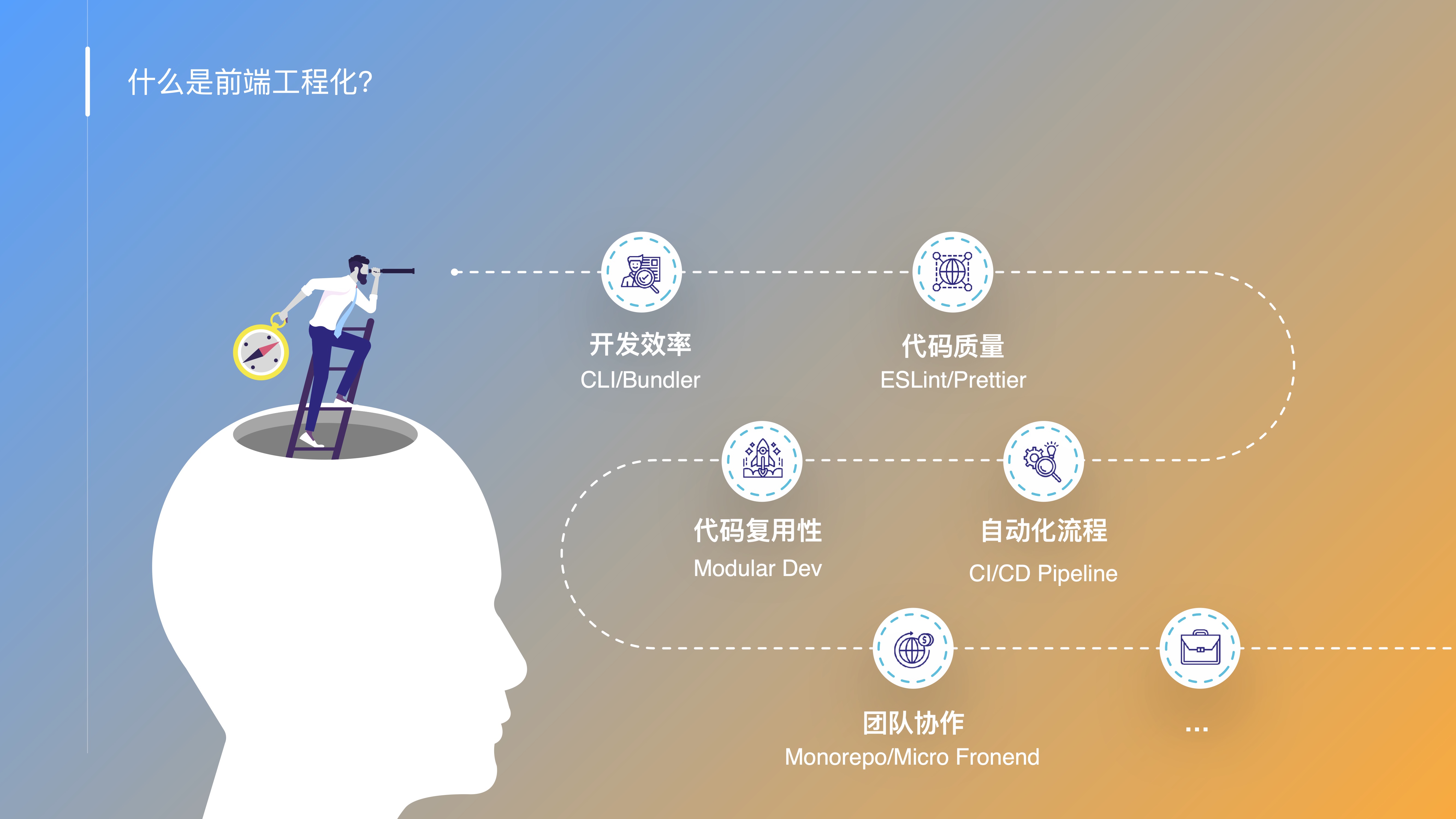
- 所谓前端工程化,就是在前端开发过程中,采用一系列的技术手段和工具,来提高开发效率、保证代码质量、提高代码复用性、实现自动化流程和促进团队协作等方面的目标,是现代前端开发不可或缺的一部分;
- 在这里呢我要特别说明一下,本次主题所要分享的并不是大而全的前端工程化,而是分享为了应对当前『新趋势』下的『新挑战』,我们所做的『新实践』,接下来一起看看,前端开发出现了哪些新趋势呢?
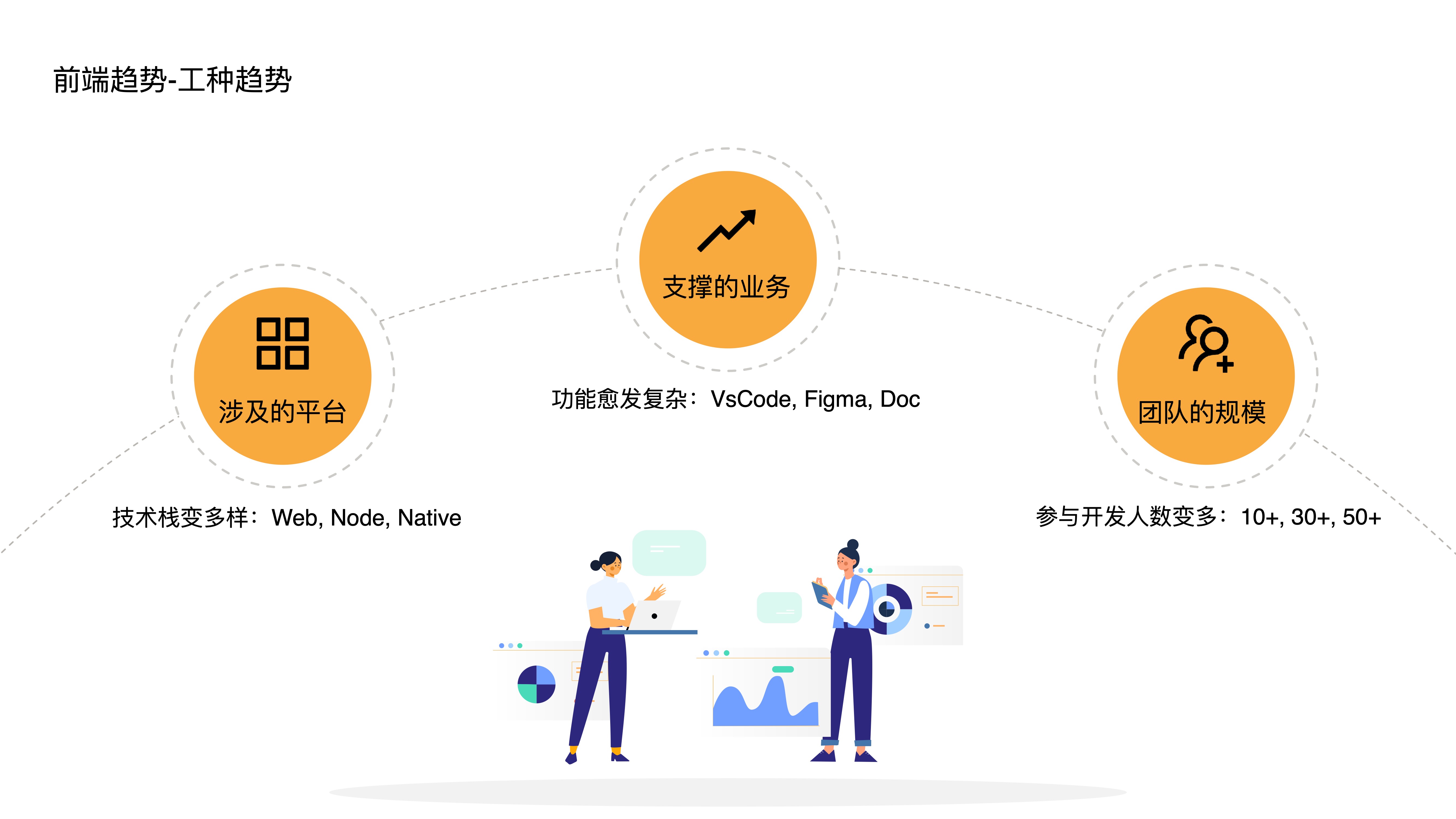
- 首先是前端工种的趋势
- 第一个趋势是涉及的平台越来越多,Web,Node,客户端和跨平台等
- 第二个趋势是所能支撑的业务也越来越多,复杂度越来越大,特别是近年来前端侧涌现出不少重前端交互的应用
- 第三个的话,是随着上述两个趋势而来地、不可避免地使得前端团队的规模增大
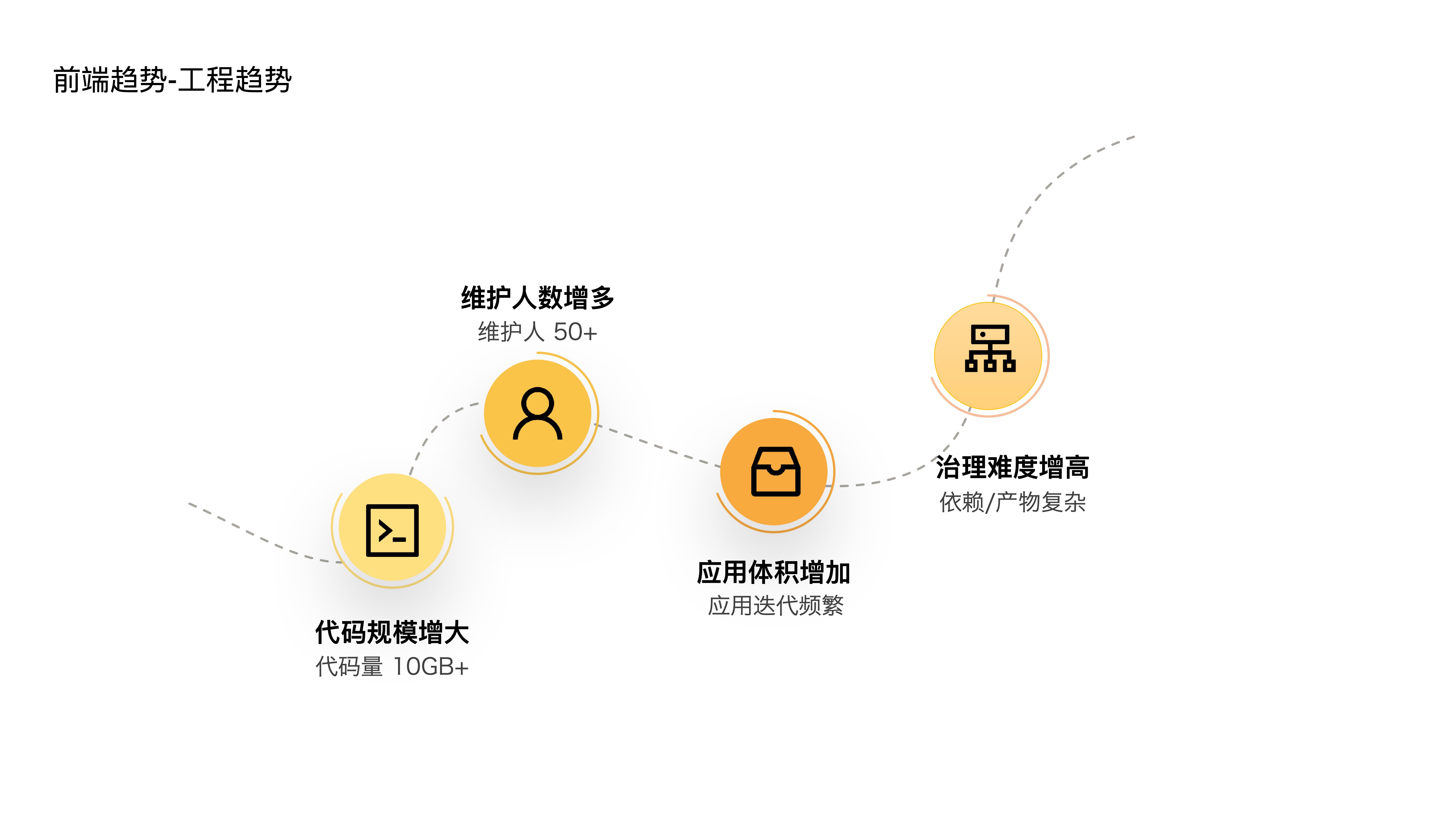
- 上述三个趋势又客观上造成了前端工程的四个趋势,也就是:
- 第一个是,代码规模增大,内部已经出现代码量超过 10G 的大型工程,同时一个应用的上下游依赖所涉及的项目数量也是非常的多
- 第二个,维护人数增多,一个工程少则十来人,多则四五十人
- 第三个,应用体积增加,随着应用功能的迭代,体积越来越庞大
- 第四个,治理难度增高,复杂的依赖关系难以治理,复杂的构建产物难以诊断
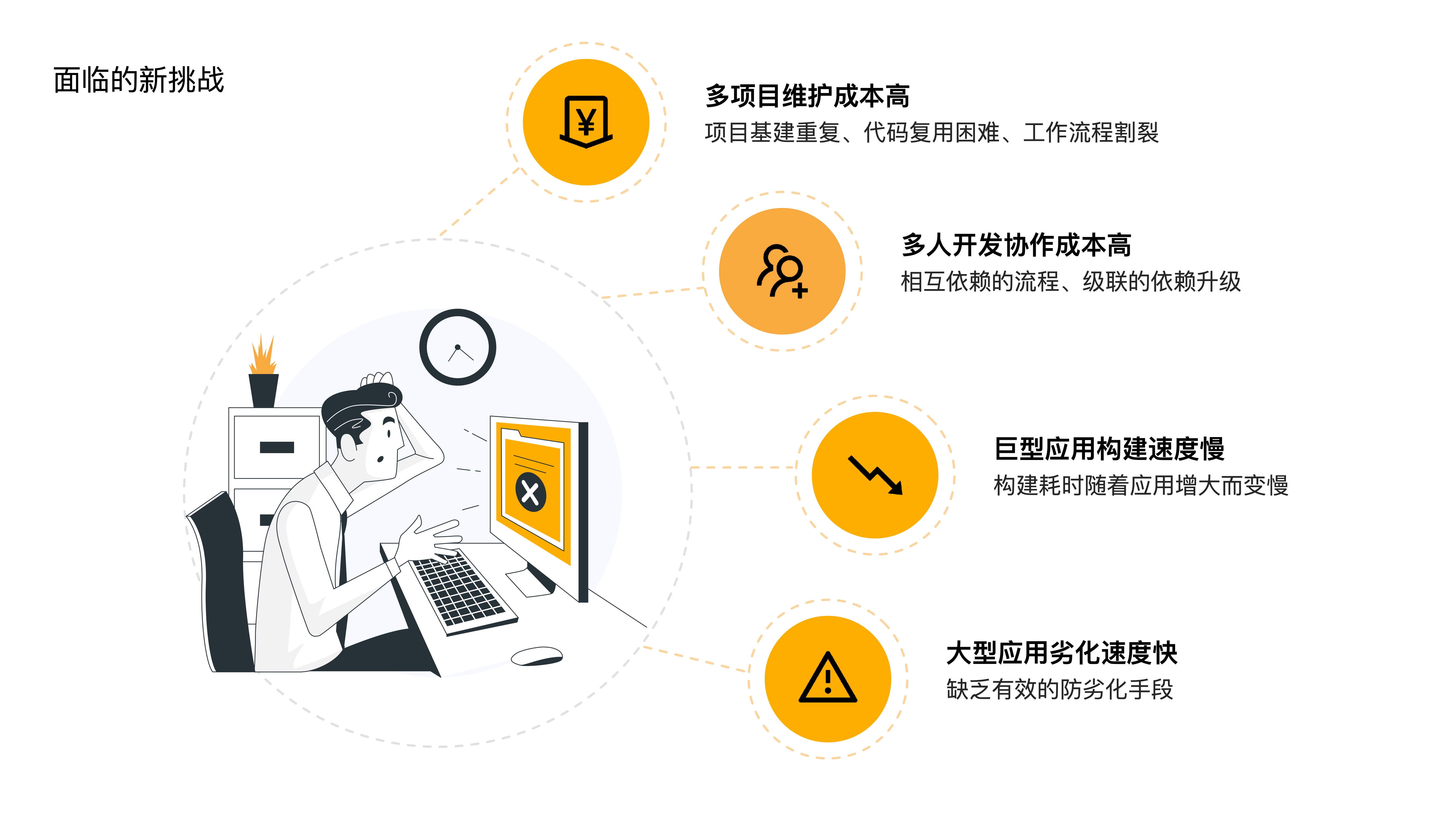
- 那么,在上述这些趋势下,我们的前端开发面临了哪些新的挑战呢?主要有四个:
- 第一个是多项目维护成本比较高,项目基建重复、代码复用困难、工作流程割裂等
- 第二个是多人开发协作成本比较高,相互依赖的流程、级联的依赖升级,都增加了协作成本
- 第三个是巨型应用构建速度比较慢,构建耗时随着应用增大而变慢
- 第四个是大型应用劣化速度比较快,我们缺乏有效的防劣化手段
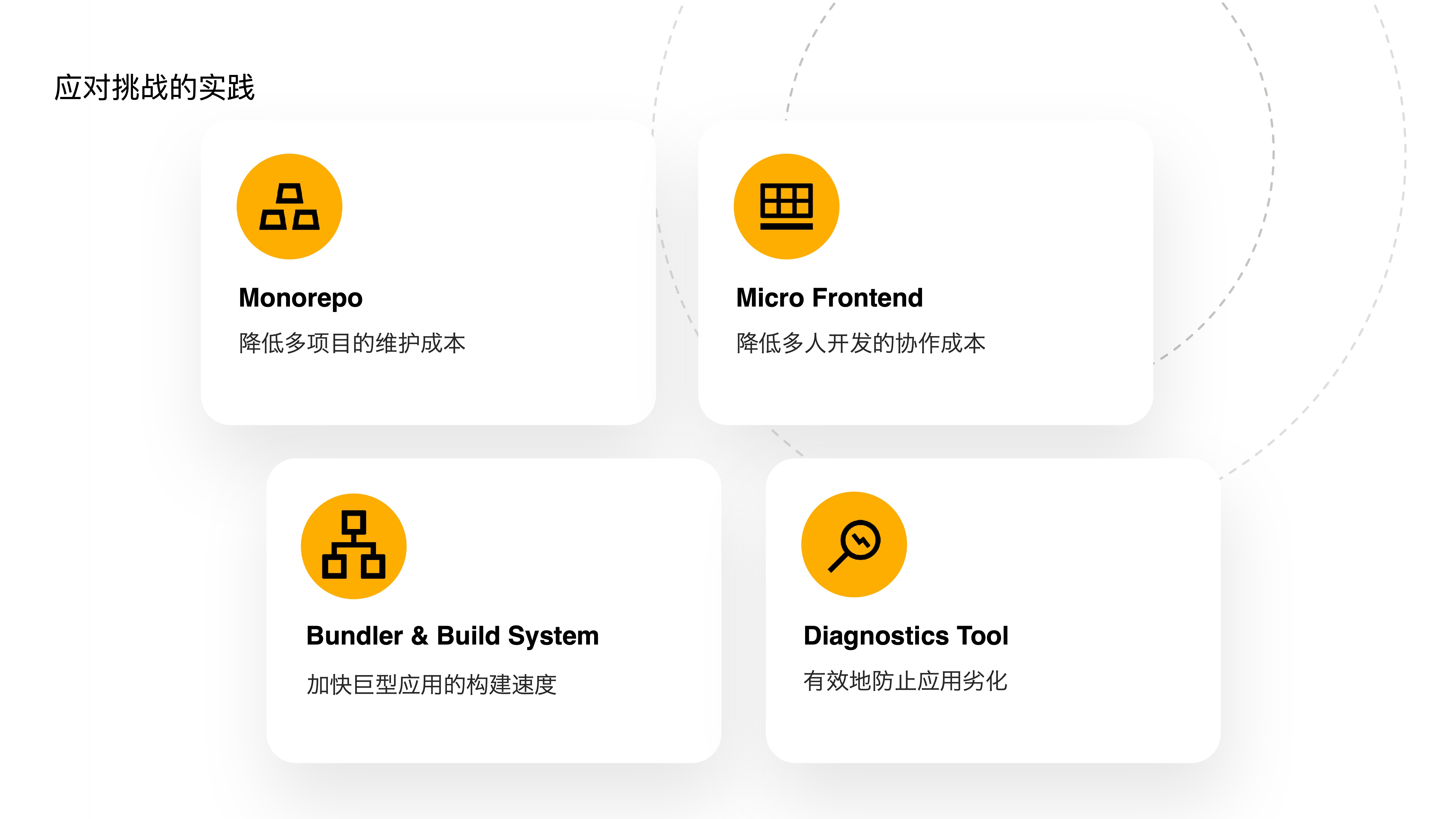
- 为了解决上述新挑战,我们投资如下工具来应对
- 第一个是自研 Monorepo 工具,用于降低多项目的维护成本
- 第二个是对原有的微前端框架进行升级,进一步降低多人开发的协作成本
- 第三个是开发 Bundler 和 Build System,来加快巨型应用的构建速度
- 第四个是提供诊断工具,来有效地防止应用劣化
- 接下来将从这四个主题展开聊聊,为了达到上述目标,我们是如何实践的
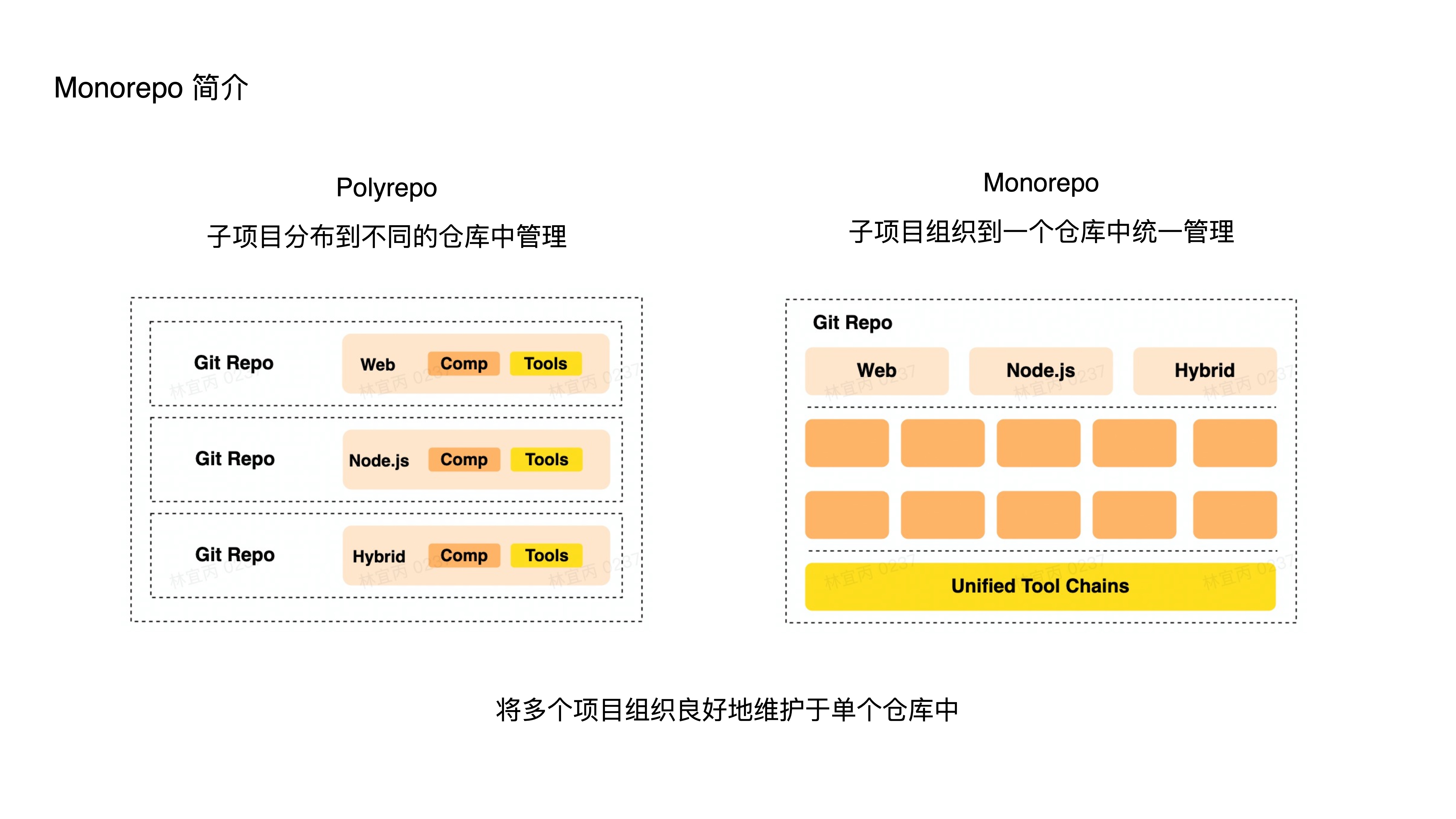
- 什么是 Monorepo?
- 它是一种源代码管理的模式,其形式就是将多个项目集中到一个仓库中管理;
- 与之相对的是 Polyrepo 模式,这种模式下各个项目都有独立的仓库;
- 简而言之,Monorepo 就是将多个不同的项目以良好地组织关系,放到单个仓库中维护;

- 那么 Monorepo 是如何降低多项目的维护成本的?他通过
- 复用基建,让开发人员重新专注于应用本身
- 代码共享,能够低成本的做到代码复用
- 原子提交,使用自动化的多项目工作流
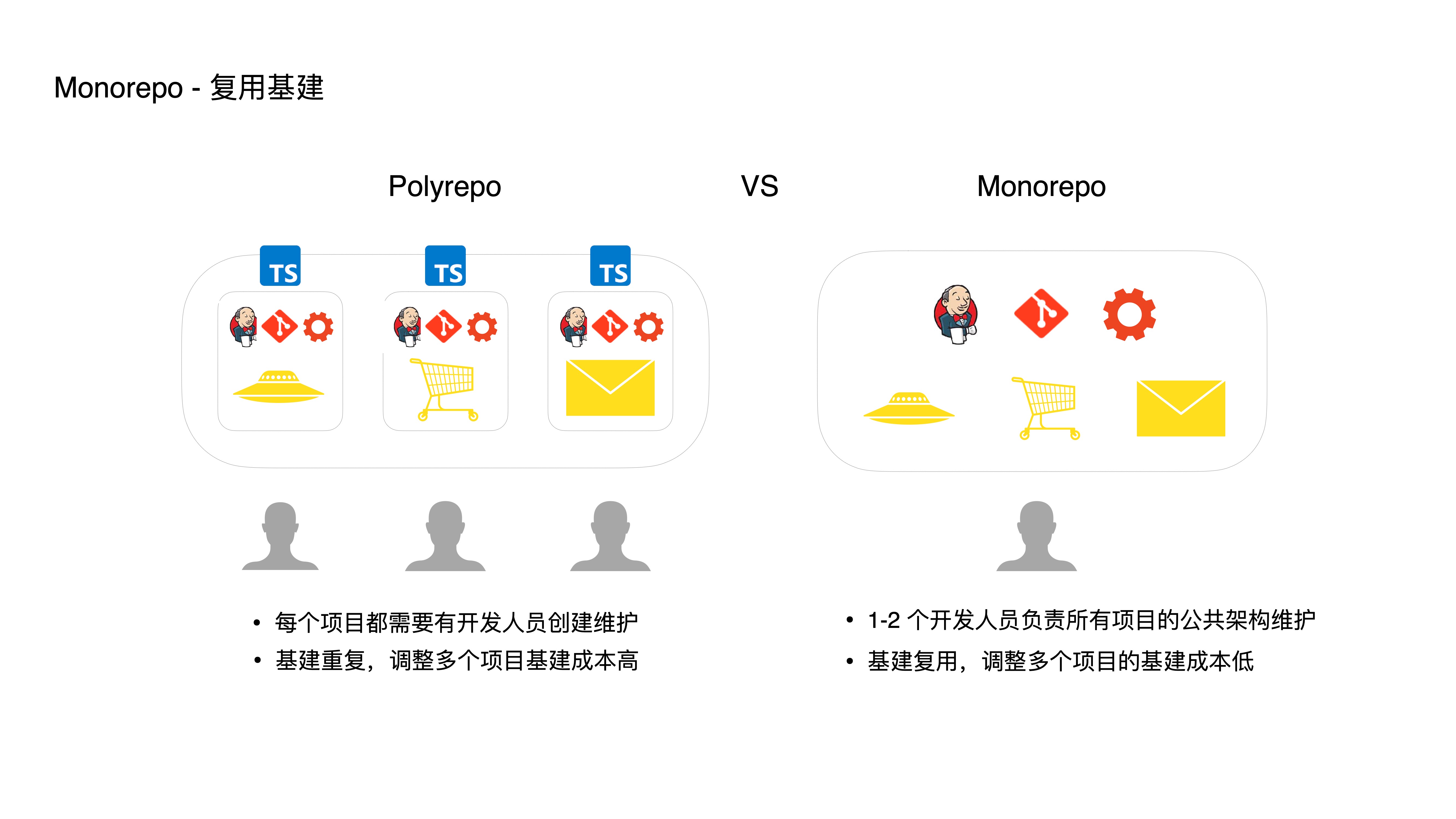
- 首先是通过复用基建,让开发人员重新专注于应用本身:
- 在传统的 Polyrepo 模式下,每个项目都需要有开发人员创建和维护;而在 Monorepo 中,只需要一两个开发人员负责建立 Monorepo 工程,所有的项目都能够在一个仓库中统一维护,通过复用一套基建(比如 CI 配置、Lint 规则、构建脚本等),从而降低多项目维护成本
- 此外,复用基建也使得统一改造和升级基建变得方便,比如想在 CI 流程中为所有项目加入类型检查,来提高下项目的质量,在 Polyrepo 下需要修改每一个项目,这样成本其实是很高的。而在 Monorepo 下,基建的调整和维护,能够很容易地应用到多个项目中。
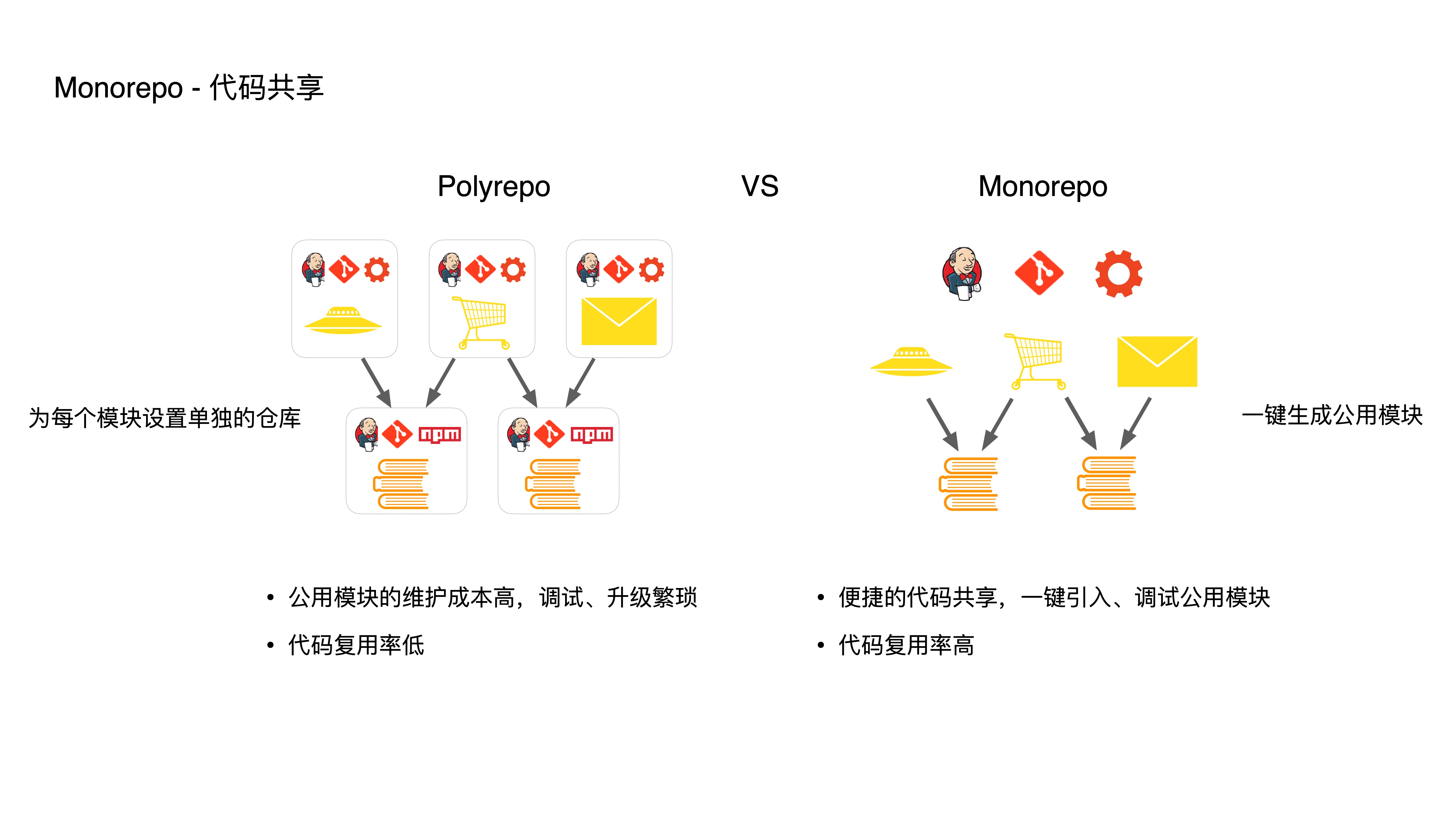
- 其次是通过代码共享,让开发人员能够低成本地复用代码:
- Polyrepo 中,维护公用模块的成本比较高,首先是调试很繁琐,公用模块的调试需要手动执行 npm link,与当前调试的项目关联起来,如果公用模块较多的话,npm link 步骤将非常繁琐低效。
- 其次公用模块的升级很繁琐,需要手动管理这种依赖关系,先升级底层的模块,然后发布,最后再升级顶层模块,如果中途出错了,我还得再来一遍这个过程。
- 而在 Monorepo 中,可以直接一键创建公用模块,顶层的模块一键引入公用模块进行开发、调试,底层模块的更改能够直接被上层感知,甚至不需要经过 link 和 npm 发布,减少了很多重复的工作,大大降低了抽离新的『复用代码』的成本,这使得大家更愿意做这类抽离工作,这反过来又提高了代码复用率。
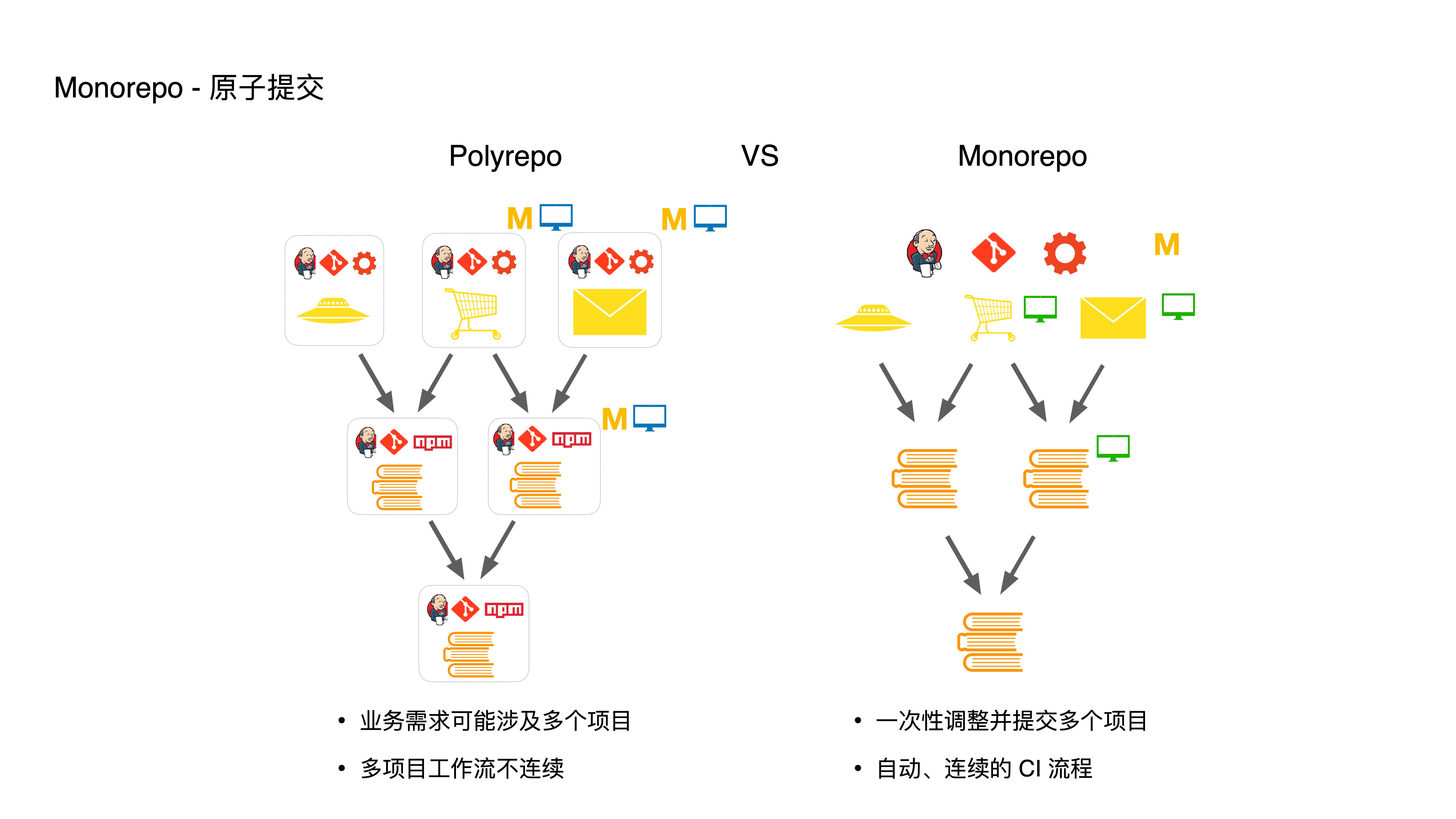
- 再次,是通过原子提交,让开发人员享受自动化的多项目工作流
- 如果我的业务需求要涉及到多个项目,在 Polyrepo 模式中,例如需要修改图中的三个项目,需要先修改提交底层模块,跑每个模块的 CI 流程,在处理顶层模块时,还得更新底层依赖,接着再跑一次 CI 流程,这一套流程非常繁琐且不连续。
- 而在 Monorpeo 中,我们可以直接一次性调整并提交多个项目,CI 和发布流程也都是一次搞定的,从而将多项目的工作流自动化。
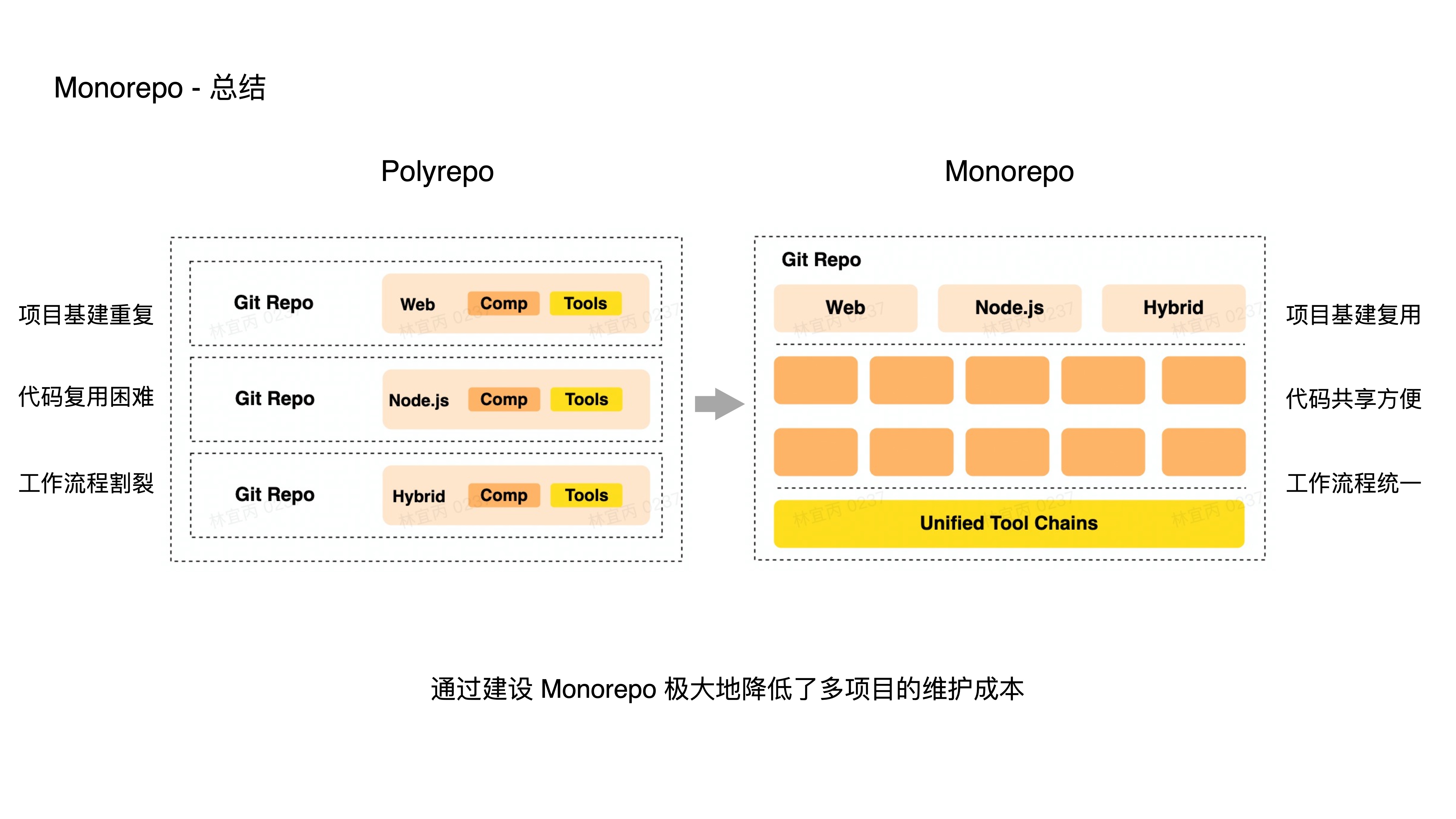
- 我们简单的做一个总结:
- 在 Polyrepo 的模式下,每一个项目都有各自的一套基建,且代码复用困难、工作流程割裂,但是在 Monorepo 里面,我们可以让多个项目复用一套基建;方便地共享代码,使用一致的工作流。
- 很多时候一个团队的项目往往不是割裂的,而是相互联系的,Monorepo 可以很方便地将这些项目组织到一个大仓库中维护,从而极大地降低了多项目的维护成本。

- 接下来分享下 bunlder 和 build stystem 的工程化实践,因为无论是单仓项目还是多仓项目,随着代码规模和子应用数量的增加,都会导致构建性能下降,为了应对这种情况,我们分别建设了 Bundler 和 Build System 工具。
- 其中 Bundler 是为了解决单个巨石应用构建速度慢的问题;
- 而 Build System 则是为了解决 Monorepo 下构建速度慢的问题。

- 在前端领域,Bundler 是一种工具,用于将多个前端资源(例如 JS、CSS、图像等文件)打包到一个或多个文件中,从而让浏览器能够直接运行;
- 常见的 Bundler 工具有 Webpack、Rollup、Vite、Parcel、Esbuild。

- 接下来介绍一下我们自研的 Rspack Bundler,它是一个基于 Rust 语言的高性能构建引擎, 具备与 Webpack 生态系统的互操作性。
- 从这句介绍中,我们可以知道,Rspack 有两个特性,一个是高性能,另一个是与 Webpack 生态的兼容性。
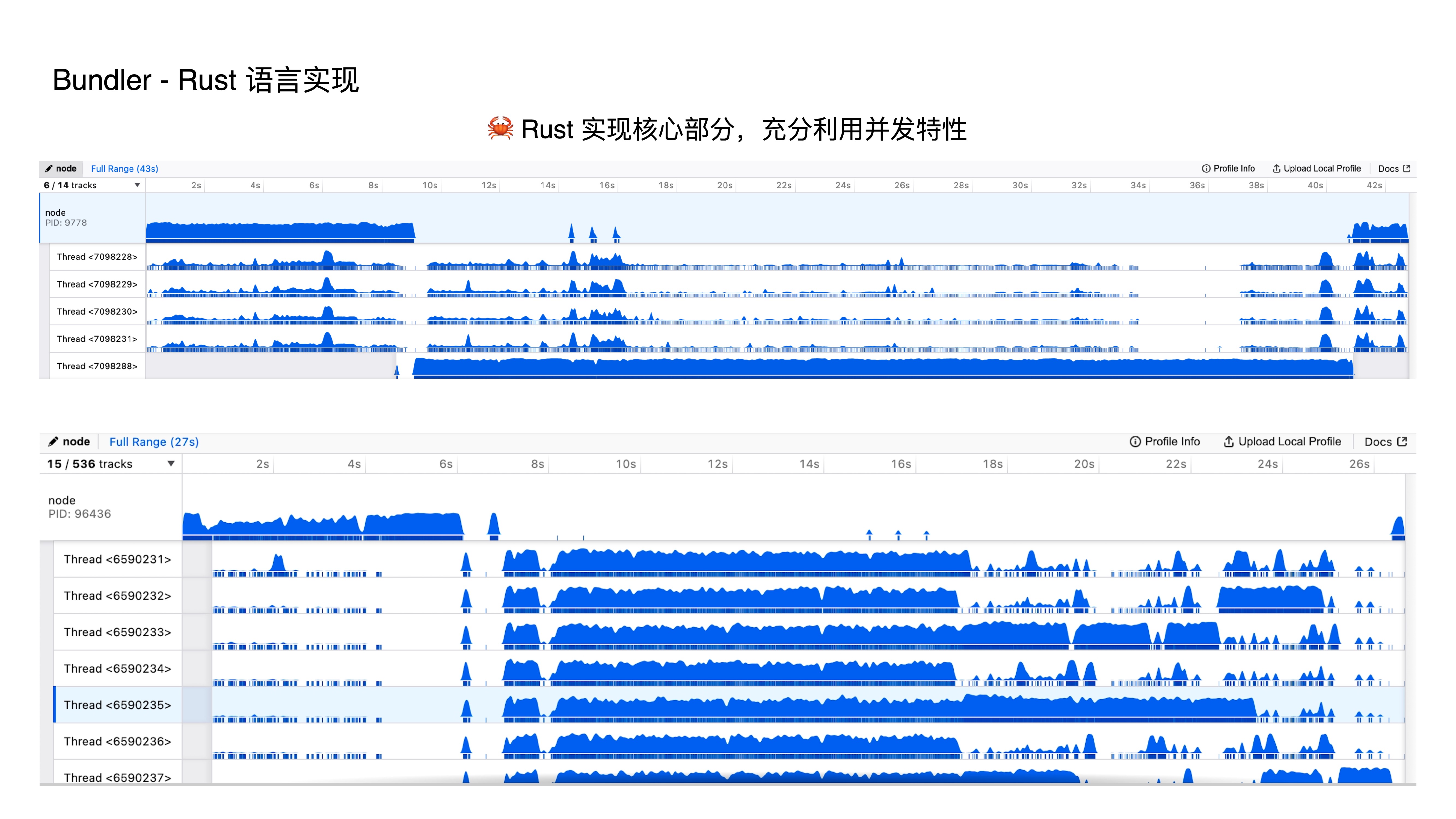
- 首先第一个特性,即采用 Rust 语言实现,由于 JS 是单线程的,虽然在 JS 中也有些方式做到并发,但这些方法都有种带着镣铐跳舞的感觉,而在 Rust 中我们能很好地支持并发特性,所以我们将构建过程中的任务,利用并发的特性去执行,这极大提升了构建性能;
- 这两张图片是 Webpack 与 RSpack 在构建过程中的线程情况对比,我们可以明显地看出,Webpack 其实只是一个单线程,而 Rspack 则能充分发挥多核 CPU 的优势,极致地压榨出性能。
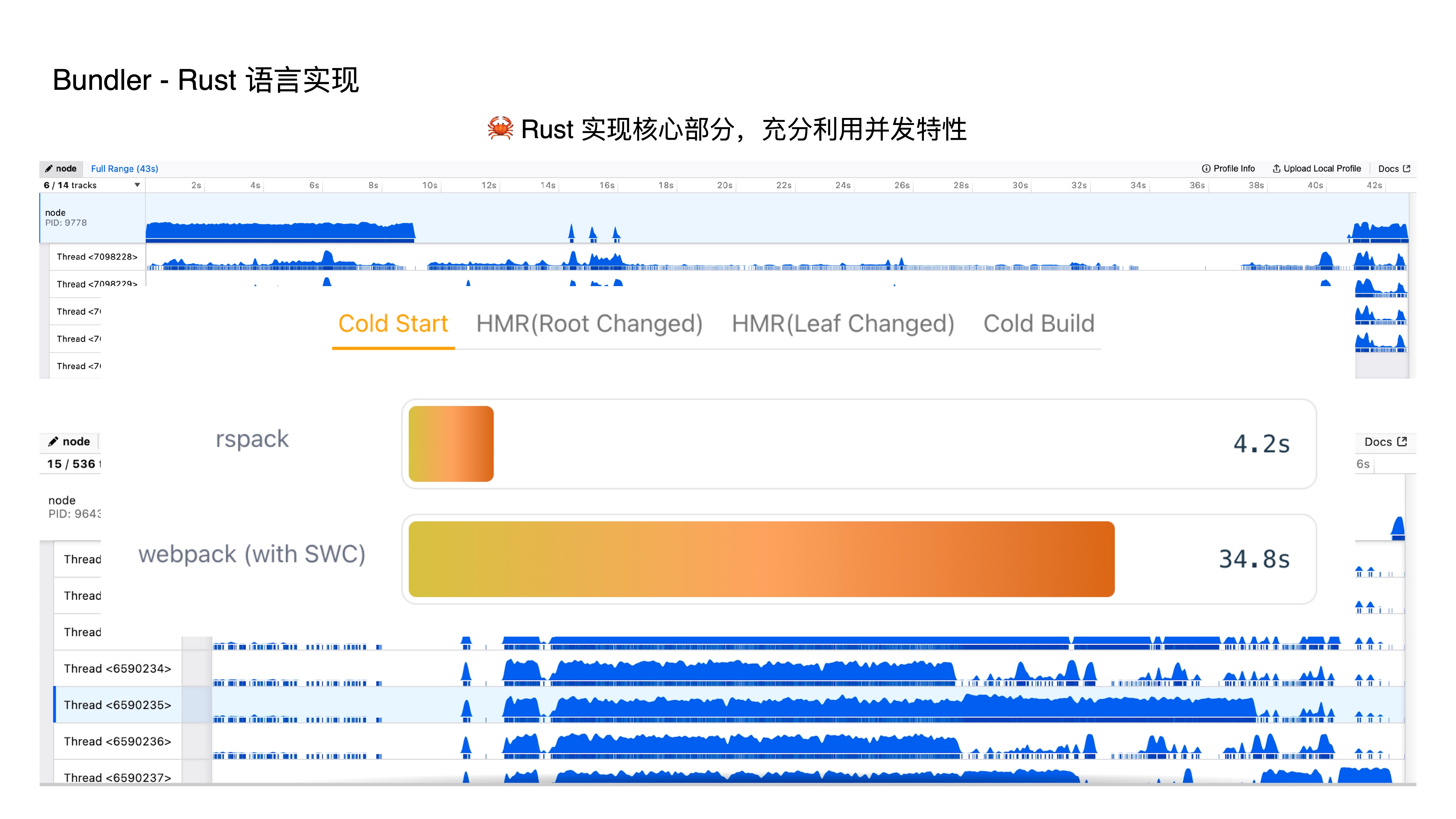
- 这是我们官网上的一个对比图,在相同的项目下,RSpack 只需要 4.2秒,而 Webpack 需要 34.8秒

- Rspack 第二个特性就是与 webpack 部分兼容,目前的实现可以理解为是一个 webpack 的子集,这套子集里包含了大部分的常用配置,满足了日常的业务开发,那么,为什么要与 webpack 生态兼容?
- 首先,webpack 的插件机制满足了项目对定制化的要求
- 其次,复用 webpack 丰富的生态,相当于用最小的成本优化巨型项目的开发体验
- 最后,存量的 webpack 项目非常多,兼容 webpack 能大大降低迁移成本
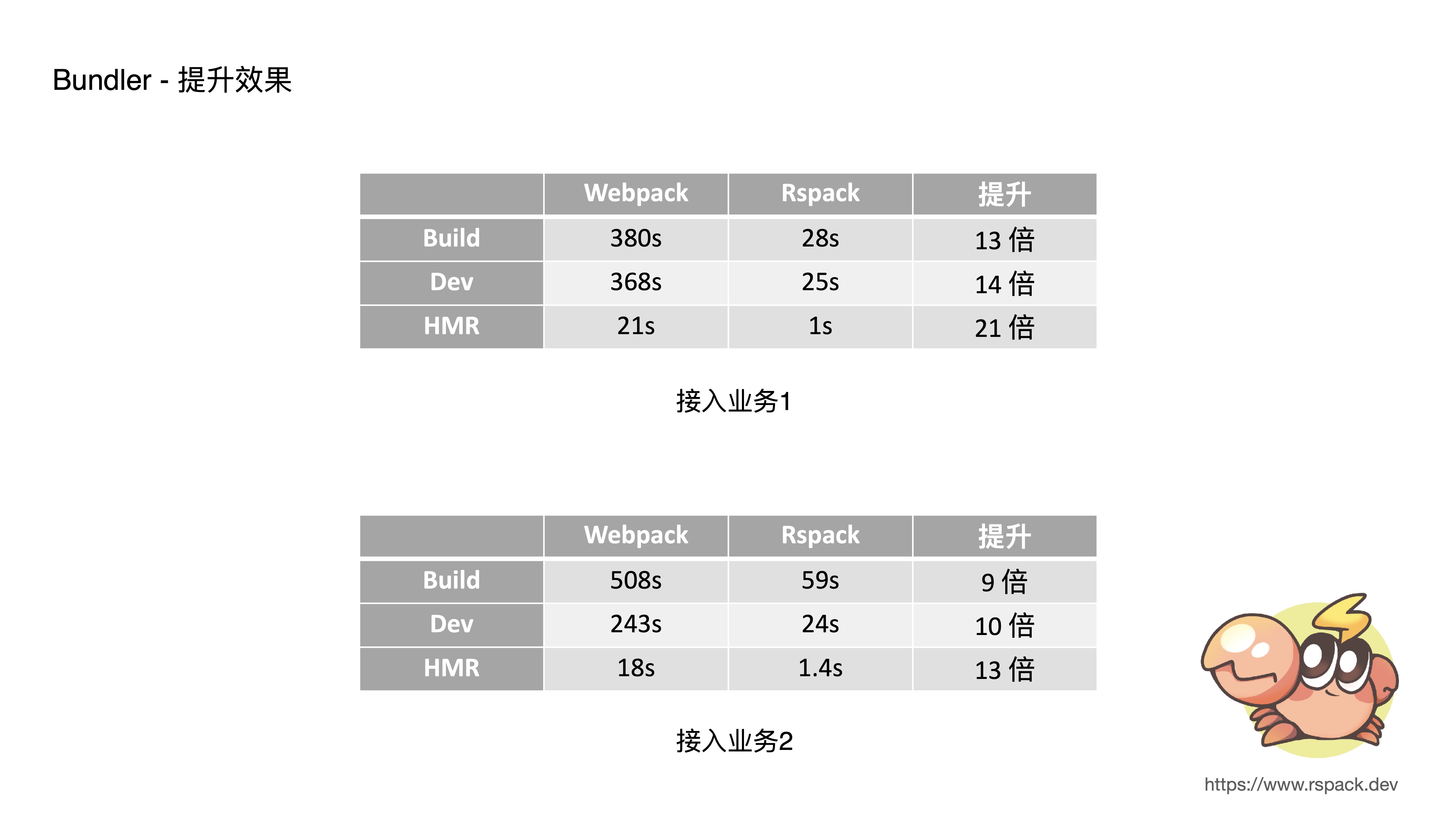
- 这是两个典型业务上的收益,两个项目原本 dev 启动耗时5分钟左右,使用 Rspack 后只需 20 秒左右,原本 hmr 需要 20 秒左右,使用 Rspack 后只需要 1 秒左右,性能收益基本都在 10 倍左右

- 简单介绍下 Build System,它通过处理 Monorepo 下的项目依赖关系图,并根据这个关系图调度构建任务;
- 为什么 Monorepo 下需要一个 Build System 呢? 因为 Monorepo 不是简单的将多个项目直接维护到单个仓库而已,它还需要借助 Build System 来管理整个代码仓库中的多个项目,并根据项目之间的依赖关系进行构建;
- 常见的 Build System 工具有 Bazel、NX、Turborepo、Lage 等
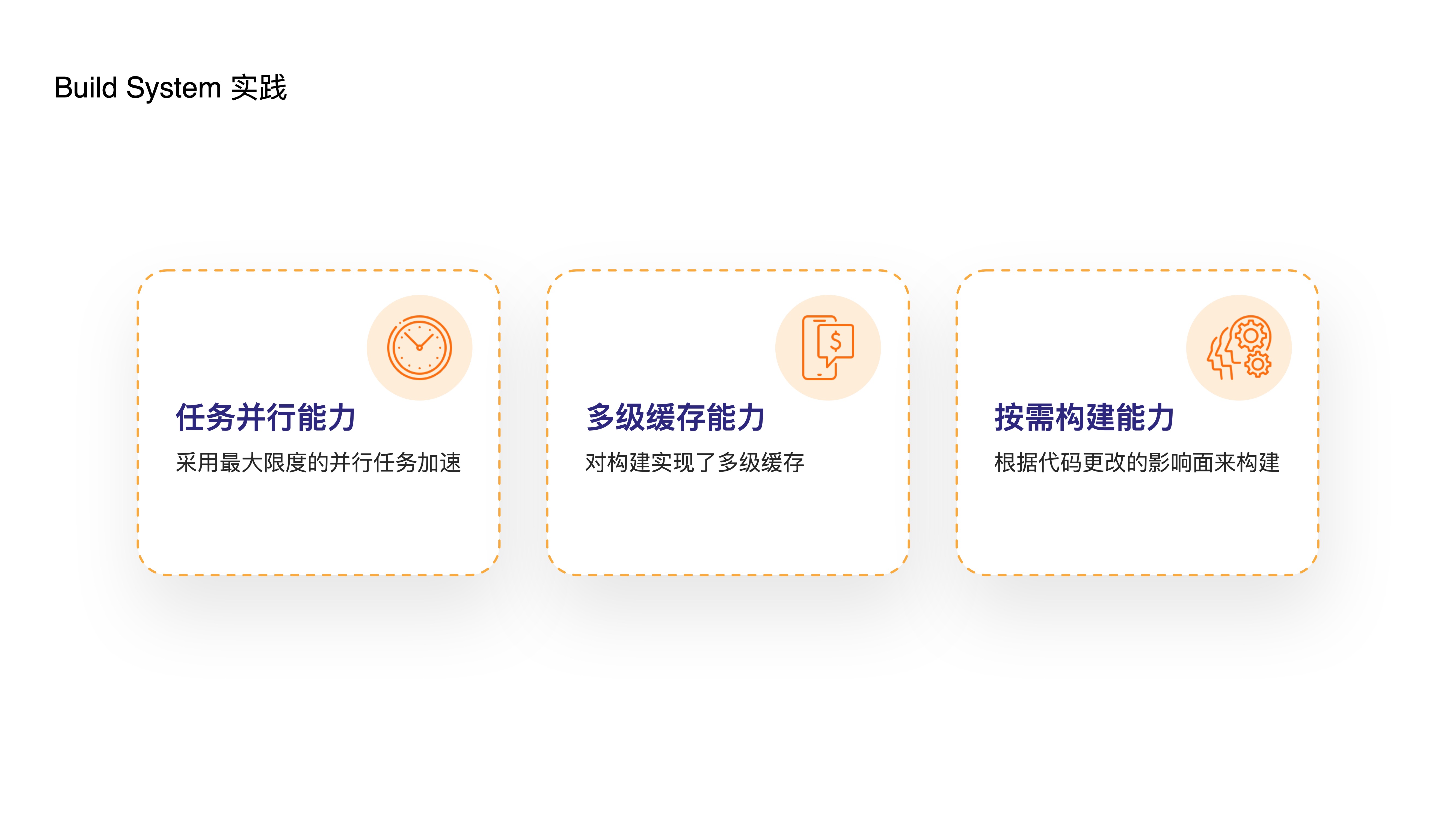
- 接下来介绍下在我们自研的 Monorepo 工具中,如何实践 Build System,我们通过
- 支持『任务并行能力』,采用最大限度的并行任务加速
- 支持『多级缓存能力』,对构建任务实现了多级缓存
- 支持『按需构建能力』,根据代码更改的影响面来构建
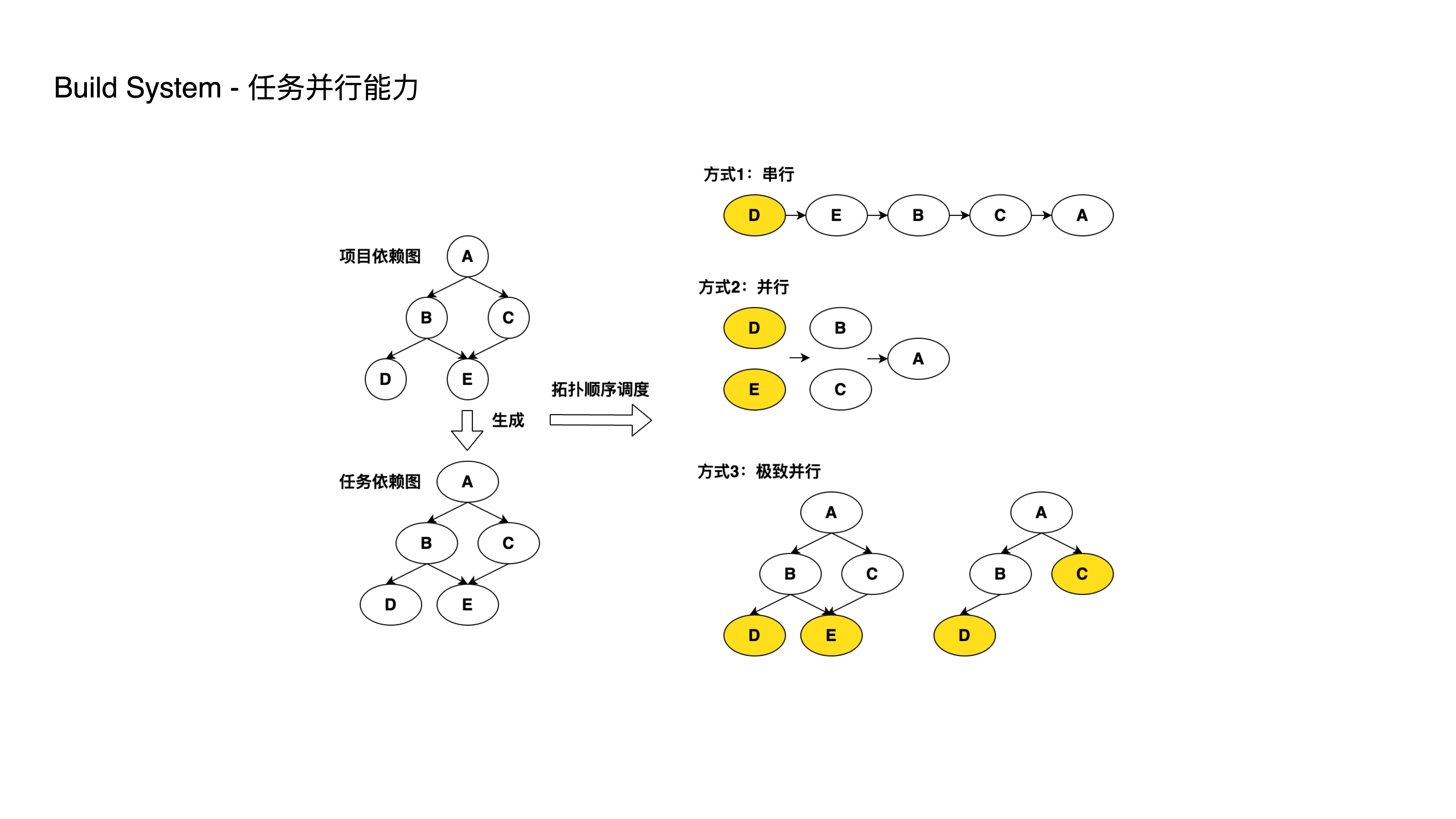
- 如图所示,根据子项目的依赖关系转成一个任务依赖图,它的构建顺序必须符合这样一种要求,即上层的项目构建,需要等待底层项目构建的完成。
- OK,我们看方式一,即通过串行排成 DEBCA,这是能够符合构建要求的;但是它的性能是比较低的,比如 D 和 E 是可以并行的,所以第二种方式就是通过把 DE 以及 BC 进行并行处理,这样便能把前面的 5 个步骤加速到 3 个步骤。
- 此时我们发现任务 C 呢,它不依赖任务 D 的完成,但是方式二下,任务 C 却得等待 D 和 E 都完成才开始执行。
- 因此便引出第三种方式,在任务 E 完成后,D 和 C 以并行方式执行;
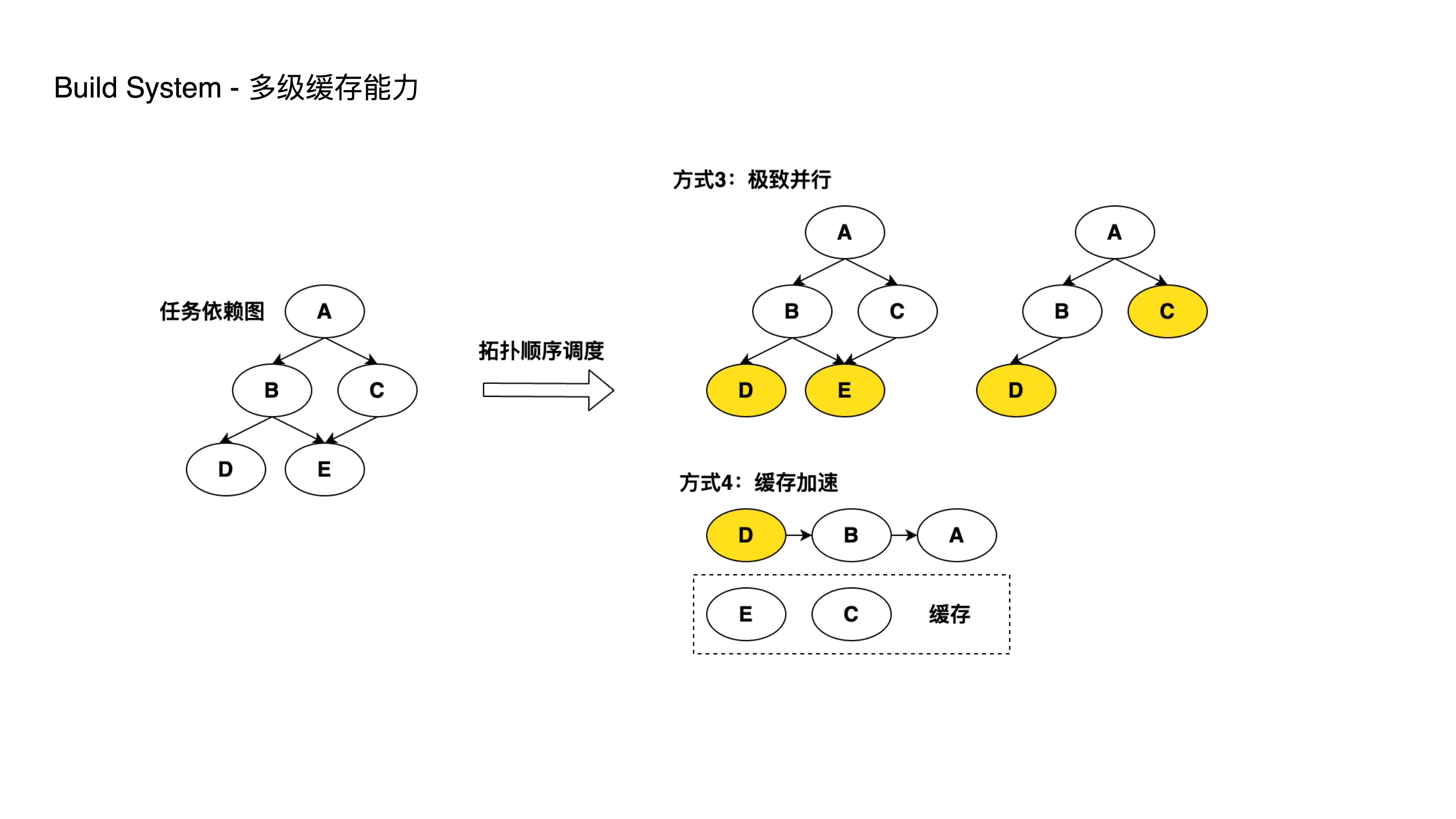
- 当 monorepo 子项目规模增大后,每一次开发或者上线都会涉及多个子项目,如果每次都需要对这些子项目进行重新构建,这将会极大地拖慢构建和部署速度。
- 我们提供了对构建产物进行缓存的能力,能够同时将产物缓存到本地和远程,当相关的子项目没有修改过代码时,将会复用之前的构建产物以减少构建时间。
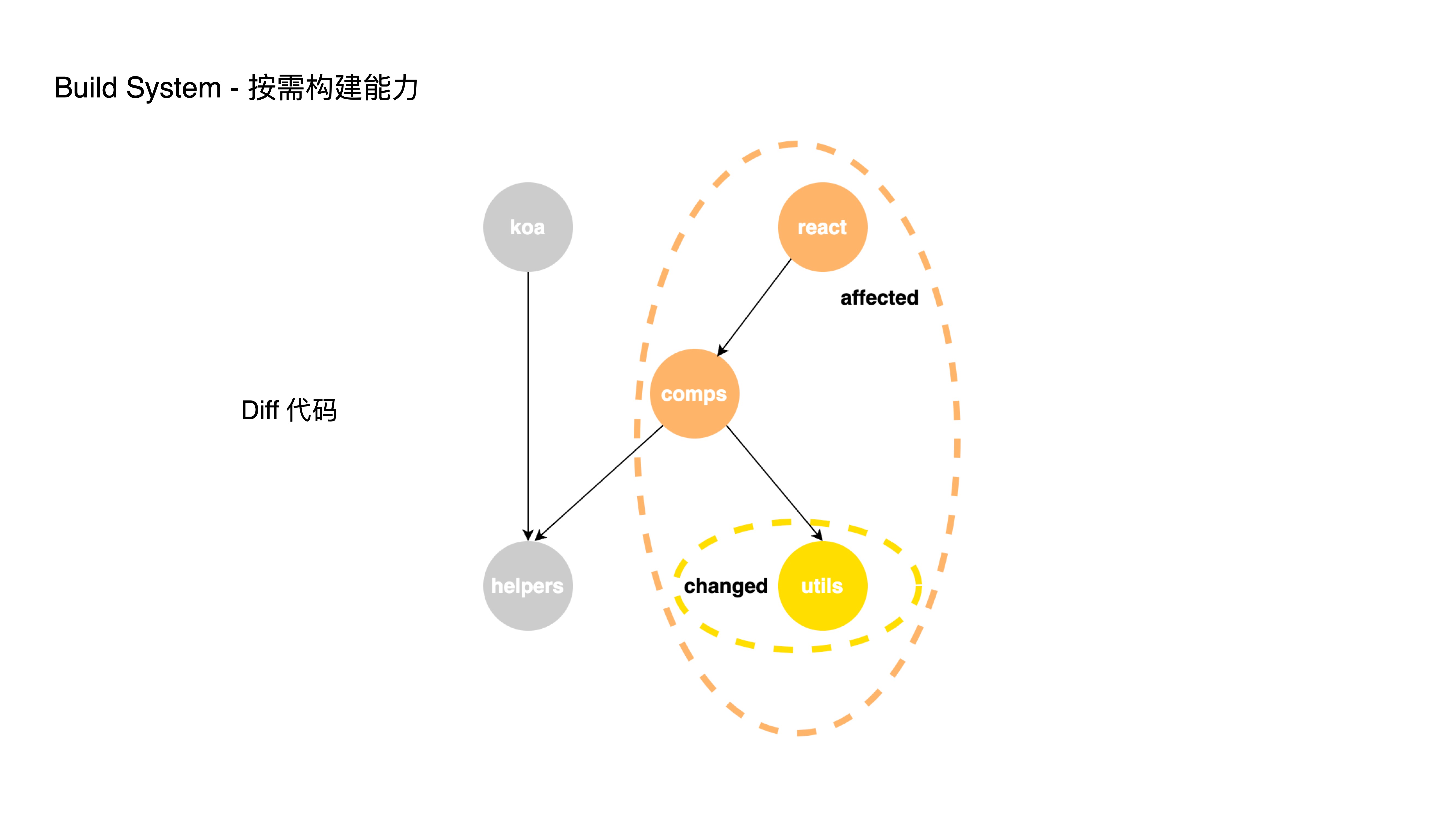
- 按需构建能力方面的实践,我们支持按影响面执行 CI 流程,通过 git diff 当前有改动的代码进行依赖分析,从而只构建受影响的项目,否则每次 CI 都会完整的构建所有的子项目。
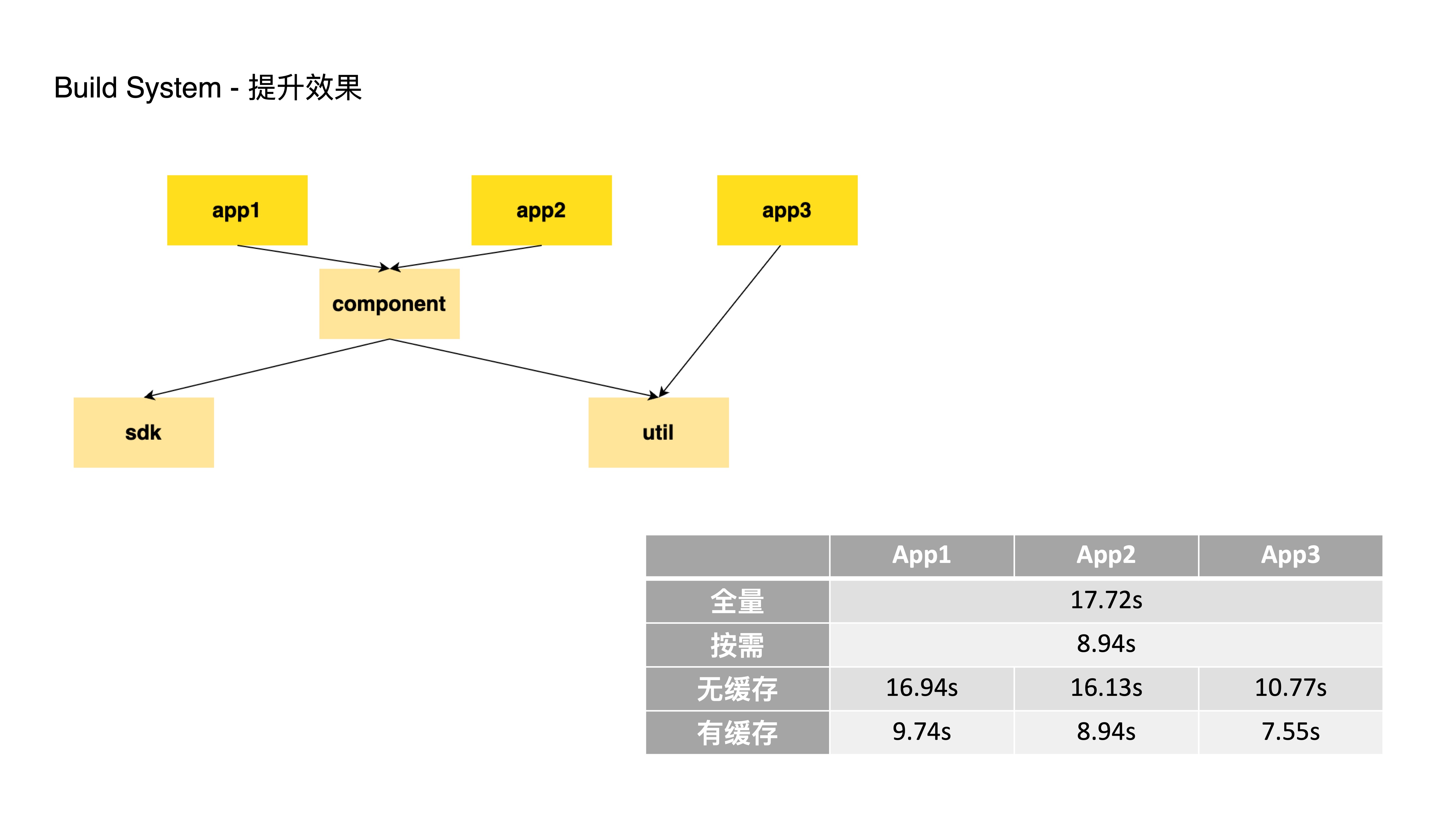
- 此处以一个简单的 Monorepo 为例,依赖关系如图所示
- 如果一次性全量构建所有项目,耗时约为 17.72秒
- 如果仅仅改动了 component 模块,那么按需构建的话,我只需要构建 component, app1, app2,此时耗时 8.94秒,节约 50% 的时间
- 再来看看无缓存的情况下,我仅仅构建 App1, App2, App3 它们的耗时在 10.77秒到16.94秒之间
- 如果有缓存的话,比如 component, sdk, util 已经构建过,那么再单独构建 App1, App2, App3 时,构建耗时在 7.55秒到9.74秒之间,大约节约 45% 的时间

- 通过 Builder 和 Build System 的建设,我们分别借助 Rust 语言的高性能和远程构建缓存能力,极大地加速了巨型应用的构建速度,但这又不仅仅是开发速度上的提升,它同时给我们的业务带来两个巨大的收益
- 拉高了一个巨石应用上限:使得我们能够开发一个更巨型更强大的应用
- 加快迭代速度:使得我们可以更快更多地做 AB 测试和功能发布
- 所谓微前端,就是前端领域的应用分治解决方案,字节跳动的微前端实践也经过 iframe, spa, 框架阶段;在实践中遇到不少问题,为了进一步降低多人协作的成本,目前进入一个新方案的探索阶段。

- 接下来看下微前端的工程化实践,新方案是如何降低多人开发的协作成本的
- 首先,通过减轻基座负担,将基座应用与业务逻辑解耦
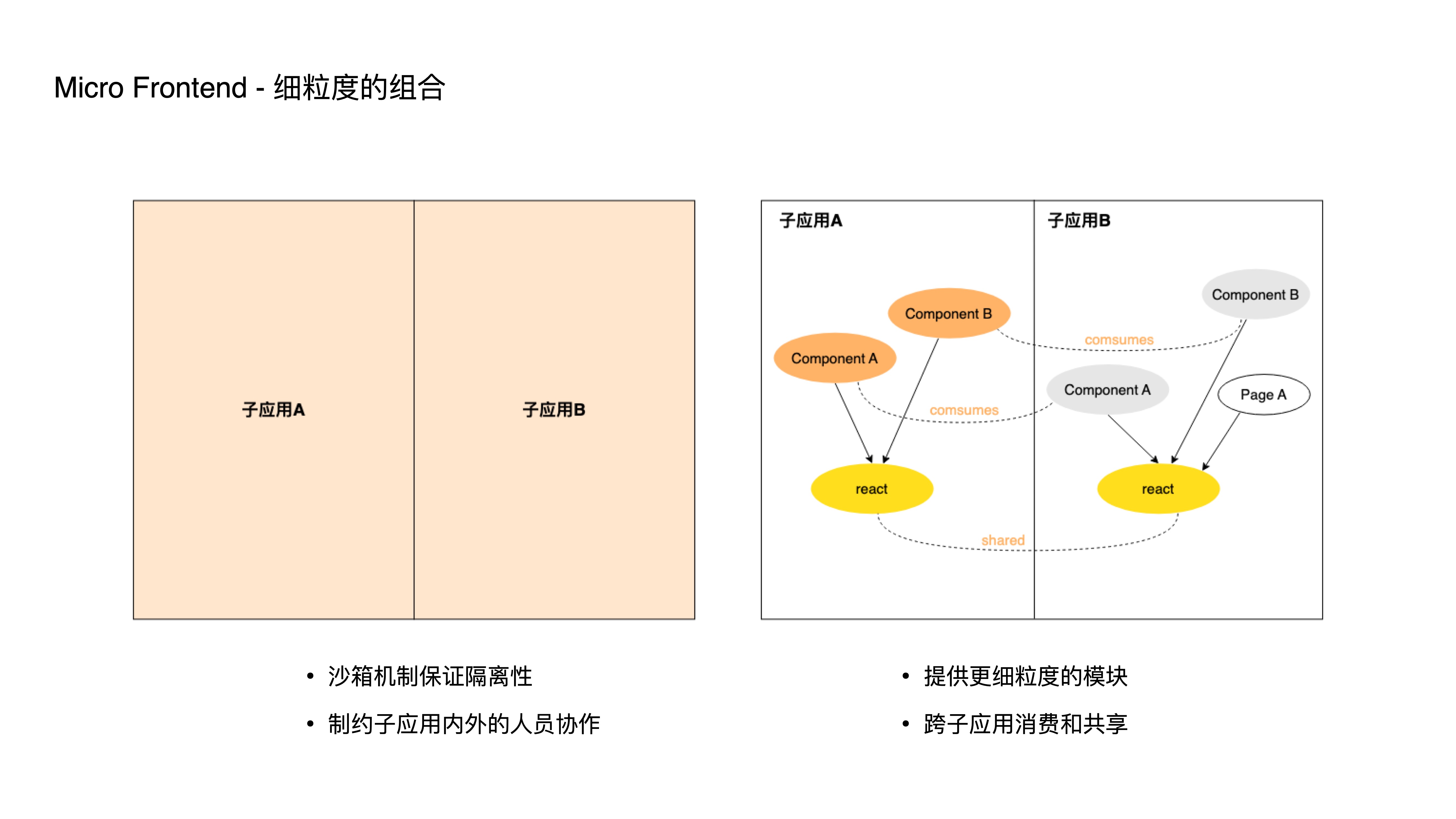
- 其次,采用细粒度的组合,在更细粒度的模块上独立开发、部署
- 最后,通过约定模块协议标准,我们搭建了模块中心,甚至可以结合低代码平台,从而带来更高的模块复用率;并支持模块级别的灰度和AB能力;
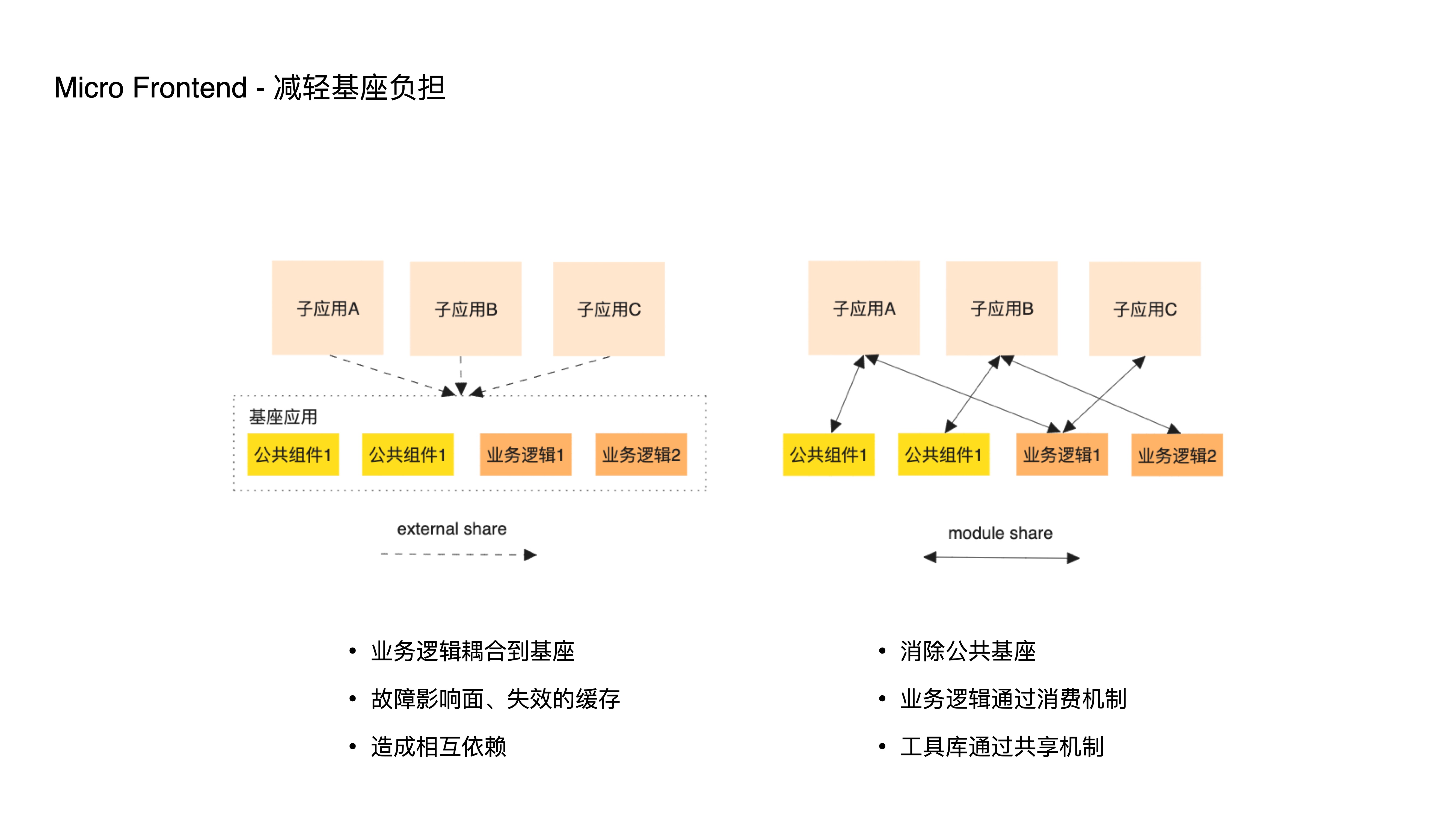
- 它是如何减轻基座负担的呢?传统的微前端,通过建立一个公共的基座来承载公共逻辑,这种复用方式,除了工具库以外,往往导致不少业务逻辑耦合到基座中,这导致基座更频繁的改动和发布,更容易出现更大的故障影响面和更容易失效的缓存;
- 这又让子应用从独立开发、部署重新回到某种程度上地相互依赖,因此,新方案通过两种方式消除了这类基座的存在,一个是消费机制,另一个是共享机制,前者一般用于复用业务逻辑,后者用于复用业务无关的工具库
- 那么,新方案的机制是如何起作用的?
- 传统的微前端架构中,多个子应用之间是相对隔离的,往往都会通过一套沙箱机制来保证这种隔离性;
- 但随着前端子应用的规模增大,人员增多,如此粗粒度的隔离又会反过来制约每个子应用内外的人员协作;
- 因此,我们新的应对方式就是通过提供更细粒度的模块消费和共享方案,从而让开发人员能够以更小的单位进行独立开发、测试、部署
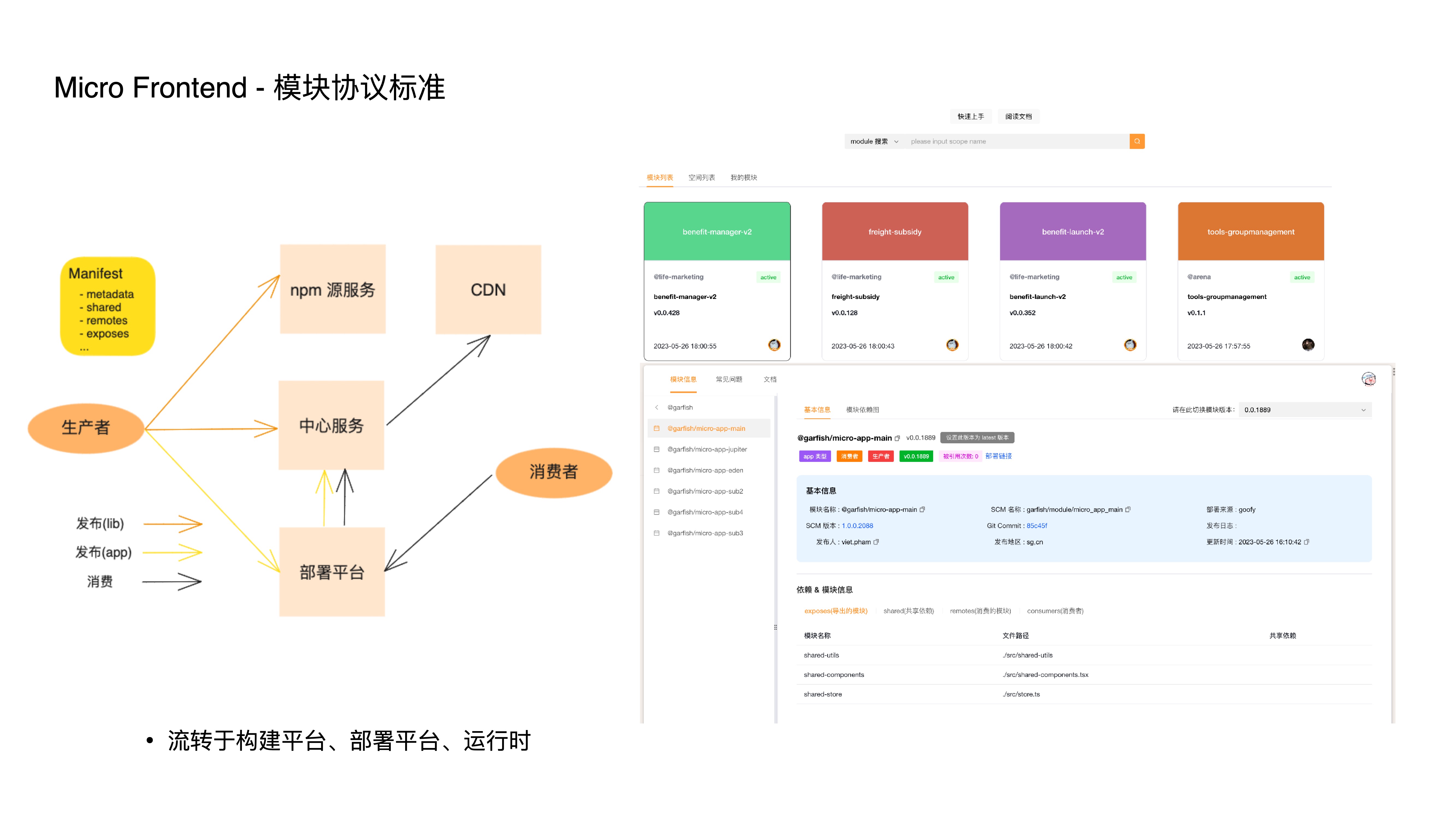
- 模块协议标准约定了模块的元信息,通过该协议在各个平台之间流转,来达到特定的功能
- 比如构建平台会根据配置文件构建出这份协议文件
- 比如部署平台会将元信息转成包含具体 cdn 地址的数据,直接回填到 html 里下发,这步操作也是能做到模块灰度和AB的前提
- 再比如应用运行时也会根据这份协议动态加载模块
- 有了细粒度组合和模块协议标准的特性,我们又能够十分方便地建立一个在线模块中心,无论是业务相关的组件,还是业务无关的工具库,都能以极低的成本在团队内部,甚至跨团队复用;
- 此外,基于这套机制,我们还尝试了与低代码平台的配合,通过低代码平台搭建出符合模块协议标准的组件,并注册为在线模块后,能够极大的提高业务开发的效率。
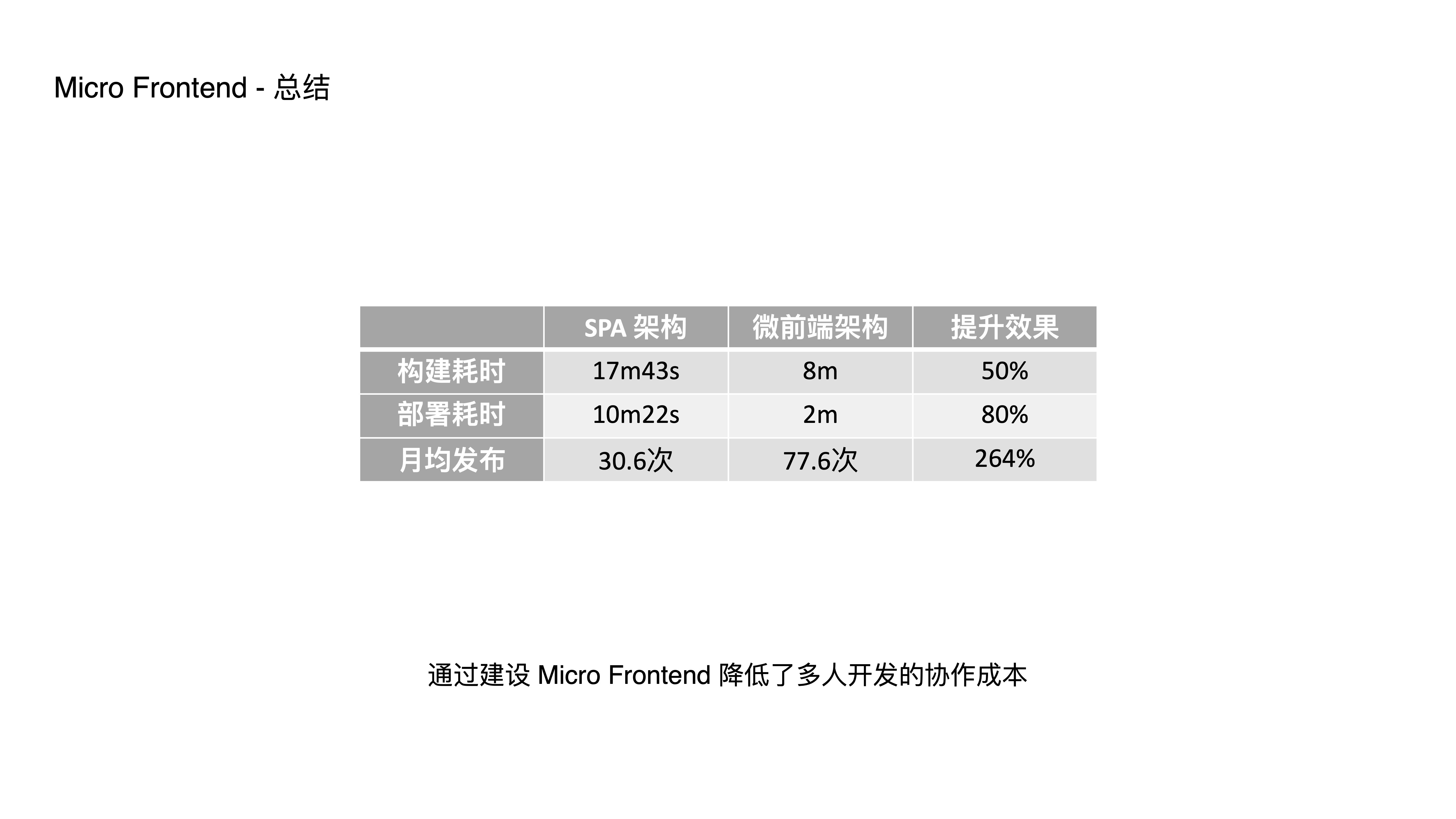
- 这是一个典型的接入业务,接入之后我们发现从构建耗时、部署耗时,甚至迭代速度和需求吞吐量都有了显著的提升效果。

- 接下来分享下诊断工具,市面上的工具大多面向构建产物进行诊断和分析,无法对构建过程进行更深入诊断和分析,作用十分有限

- 那么我们自研的诊断工具,是如何有效地防止应用劣化的呢?
- 首先,提供面向构建过程的分析能力,由于记录了构建过程的数据,我们会有更细粒度和更丰富的分析;
- 其次,提供一套可扩展的规则机制,让不同的垂直场景和业务场景能够扩展自身的规则;
- 最后,通过与核心研发流程结合,让规则真正发生作用;
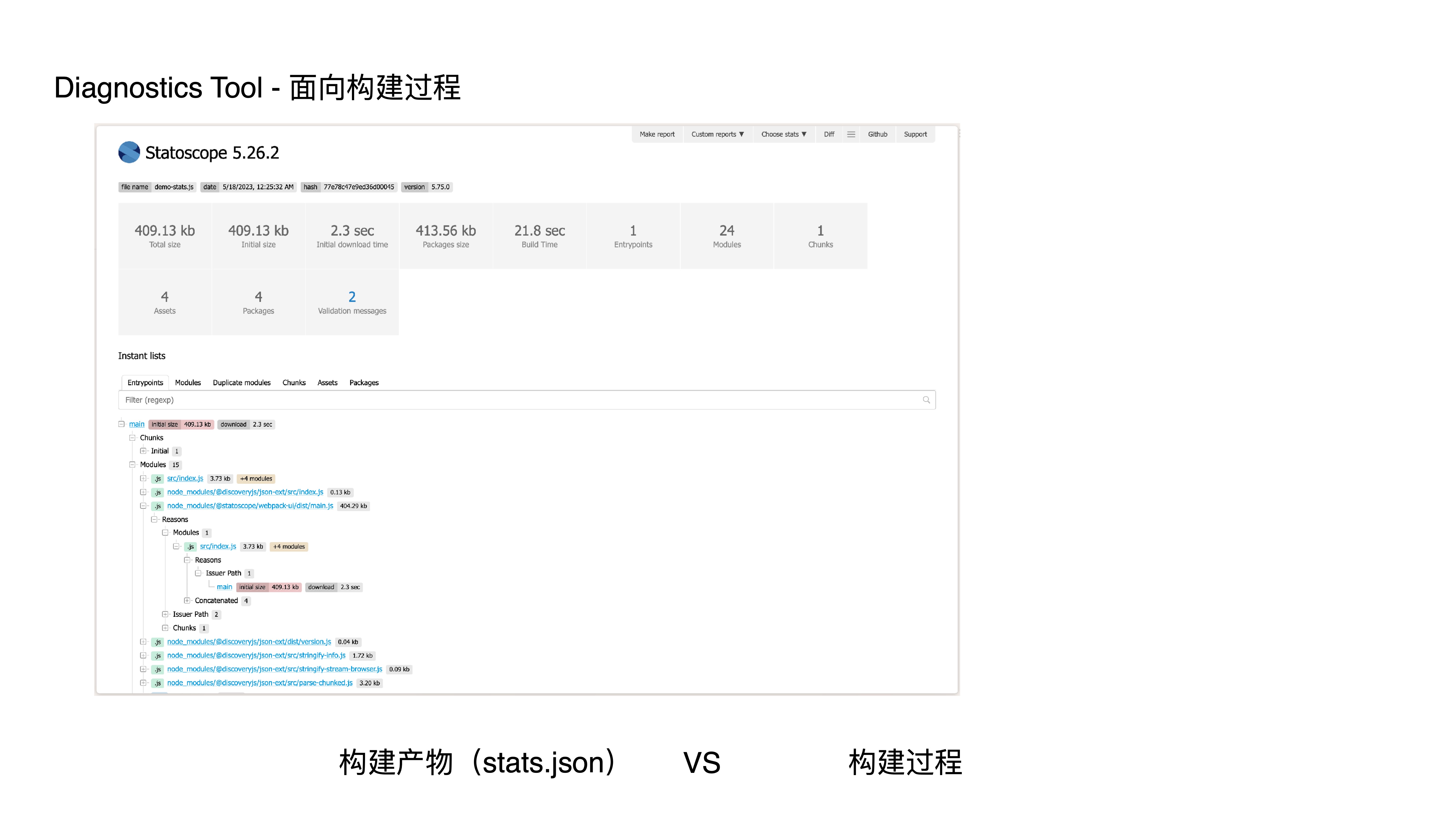
- 这是一份 statoscope 的分析结果页面,它是典型面向构建产物分析的,即通过消费 stats.json 来分析产物;
- 它没有 loader、resolver、plugin 等和构建过程相关的分析和诊断;
- 而我们的工具能做到如下一些能力:

- webpack loader 时序分析
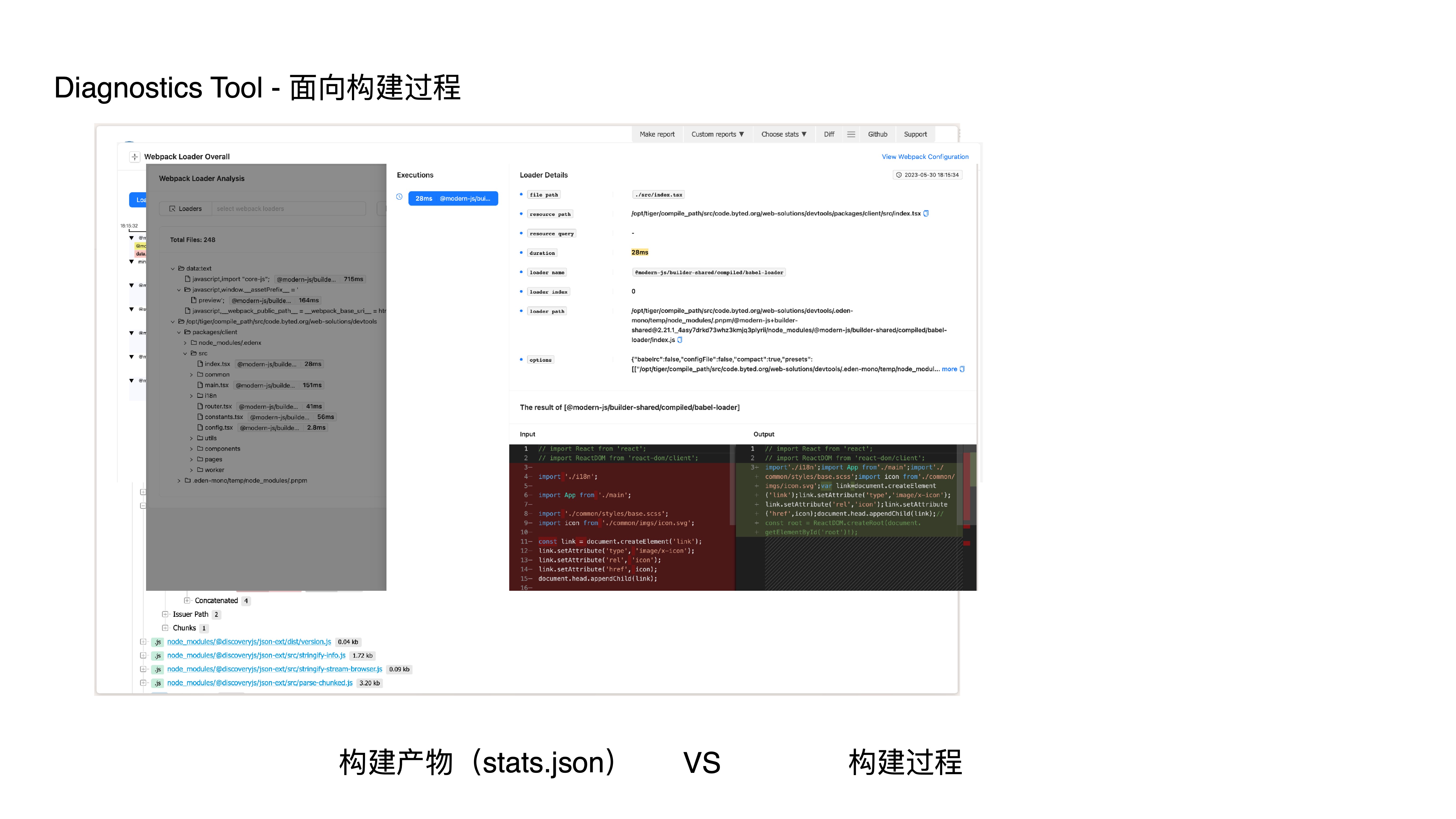
- webpack loader 分析

- webpack resolver 分析
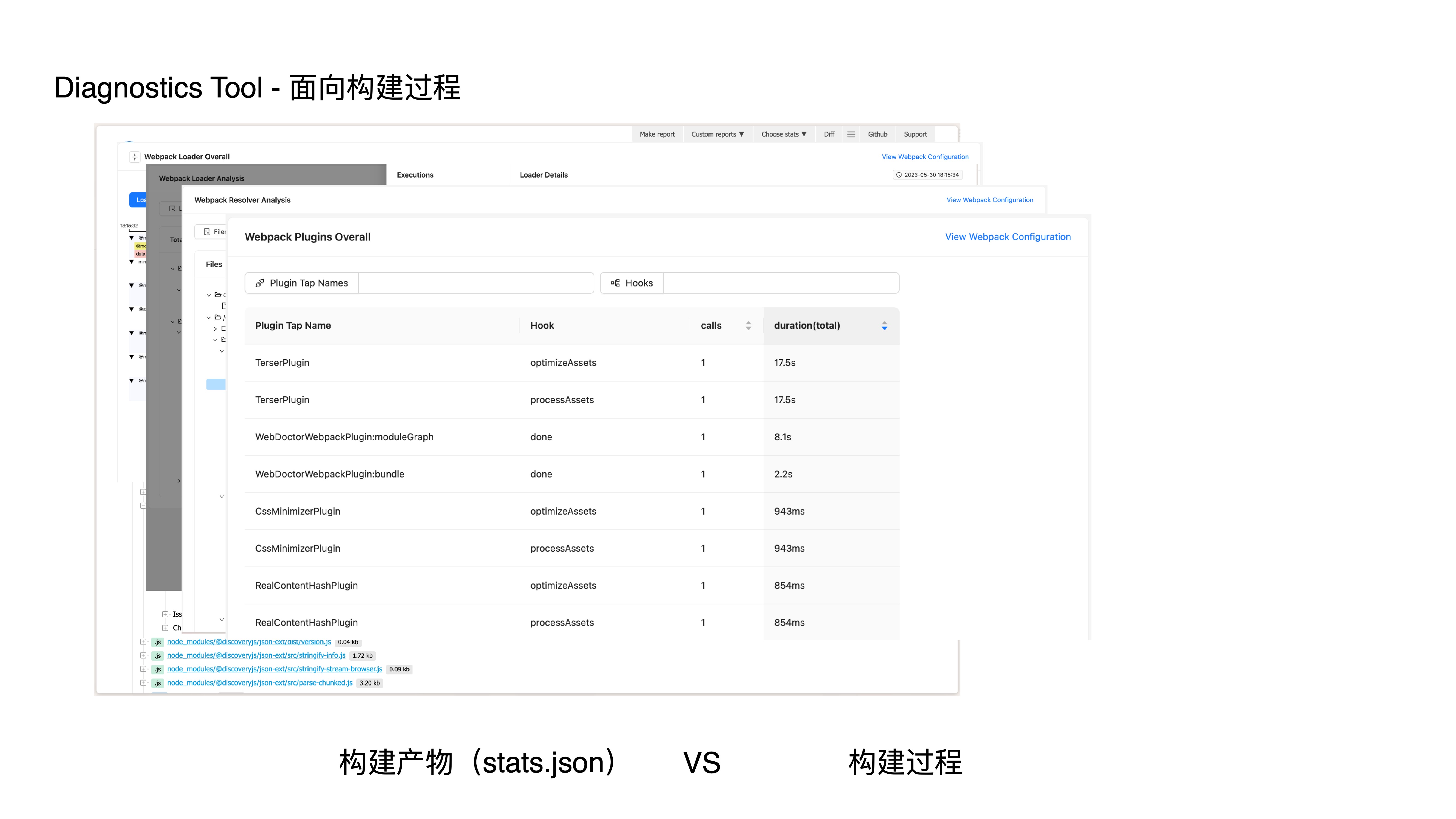
- webpack plugin 分析
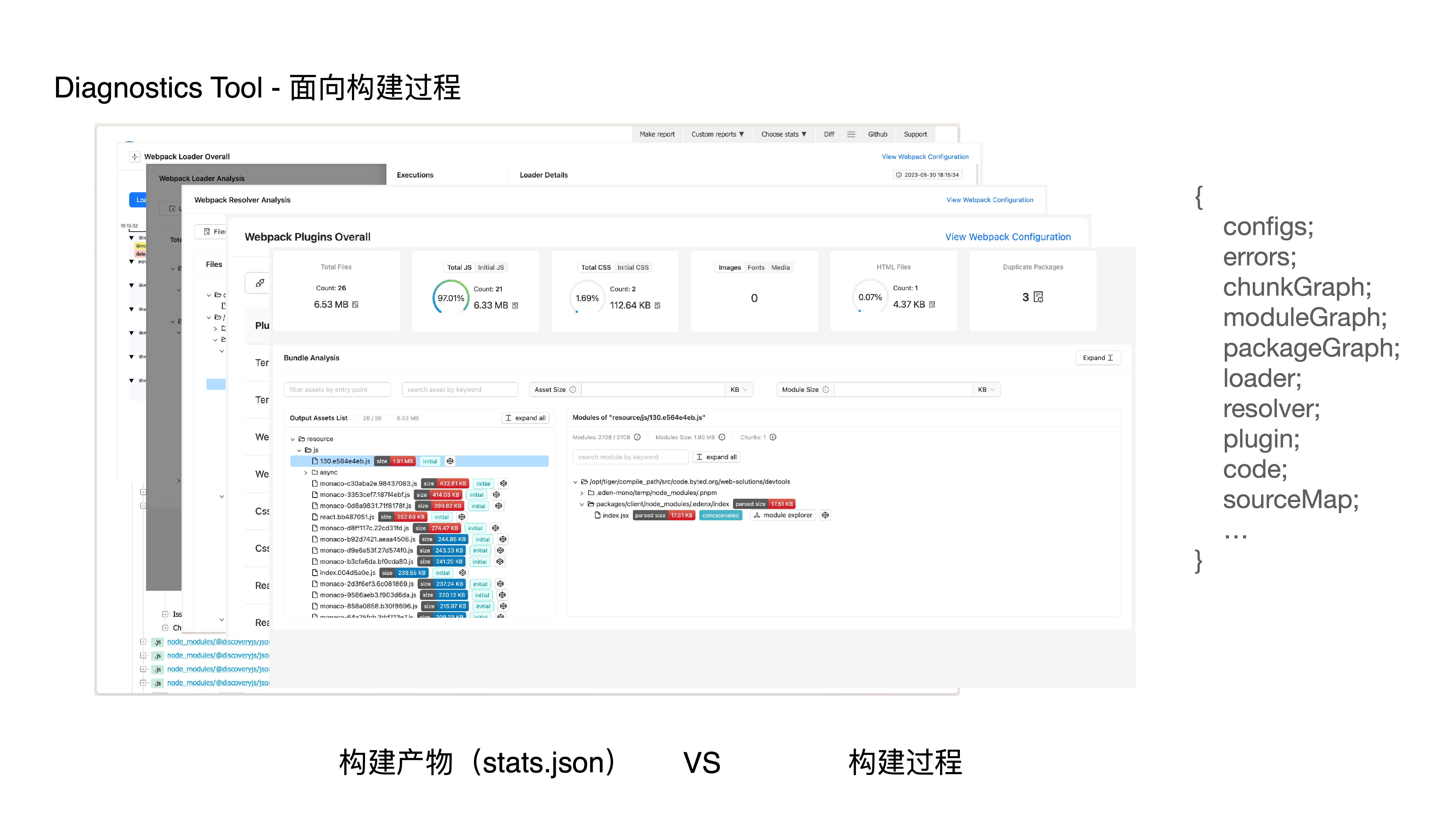
- bundle 深度分析
- 那我们是如何做到的呢?我们通过监听插件钩子和劫持 Loader 等方式介入构建过程,并收集和生成专门用于诊断和分析场景的数据结构,比如依赖图、模块图、三方包图、源码、loader、plugin、resolver 等数据,从而获得更完善的构建上下文信息,以便我们后续进行深度的诊断和分析

- 我们提供了一些默认的诊断规则,比如
- 重复包检查 - Duplicate Packages
- 包规范语句匹配 - Default Import Check
- Loader 性能优化 - Loader Performance Optimization
- 此外,我们还提供一套可扩展的诊断规则机制,我们将重新生成的数据结构作为上下文传递给自定义的规则,便能轻松的做到如下能力:
- 依赖的引用方式检查
- 特定依赖的版本检查
- 禁止使用特定的语句
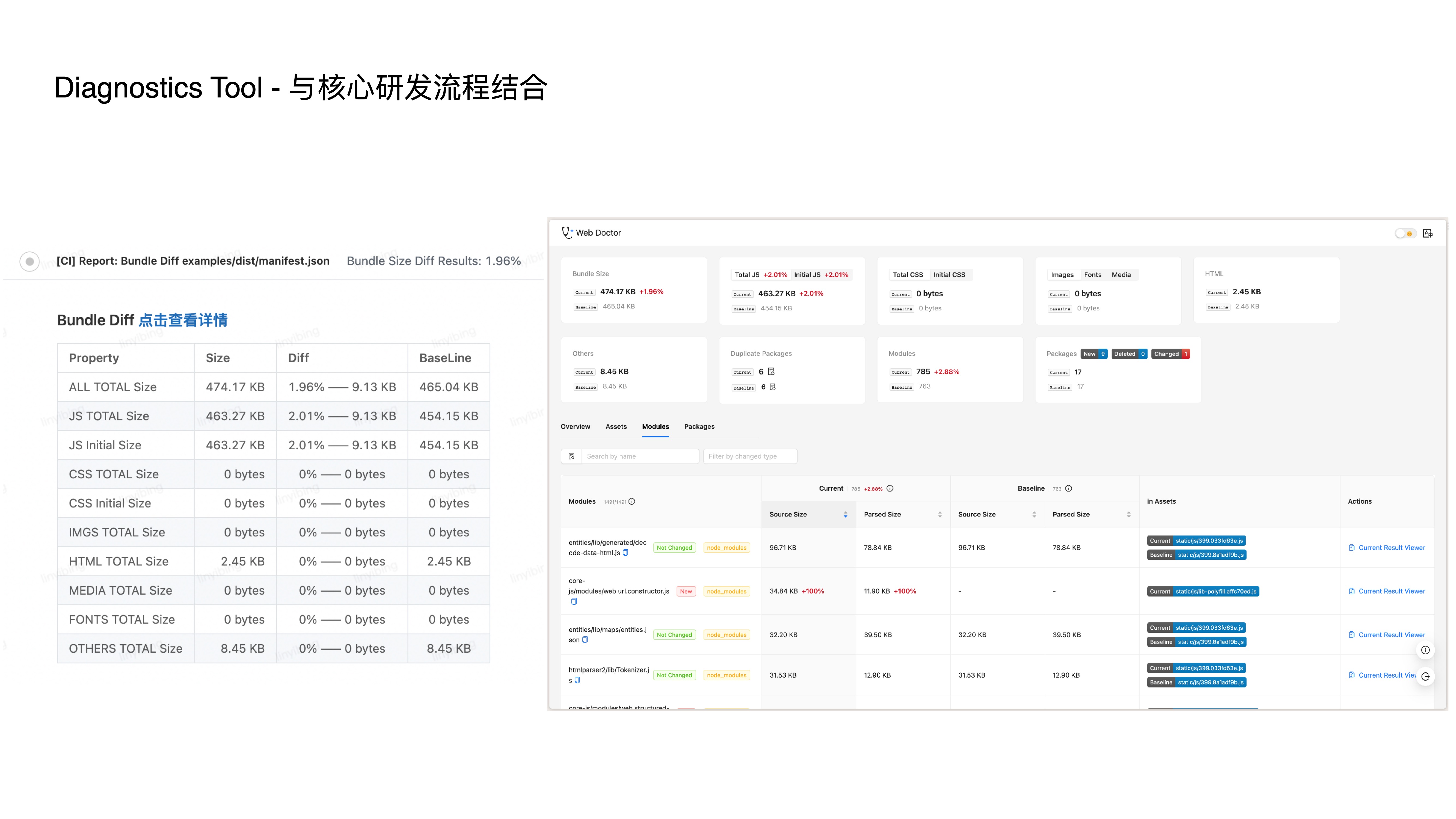
- 光有上述两个能力还不够,我们还谋求与核心研发流程结合,在 CI 中支持基于分支的 diff 拦截,从而让规则真正发生作用

- 总结一下,这是一些典型的业务收益情况
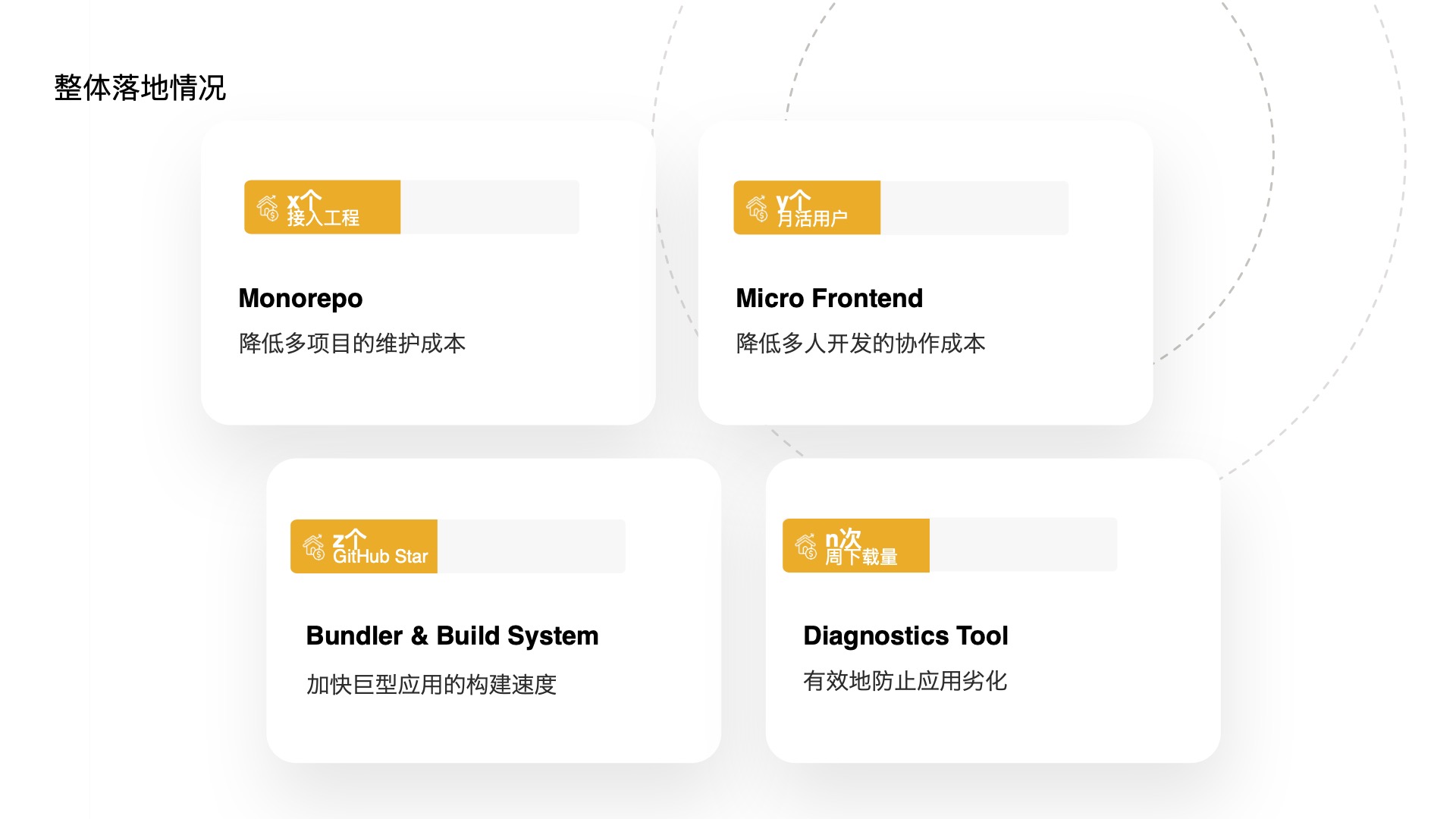
- 这是目前上述几个工具的整体落地情况,其中 Monorepo 工具接入工程x个,微前端活跃用户y个,Bundler 开源工具 Rspack z stars,诊断工具的周下载量达到n次
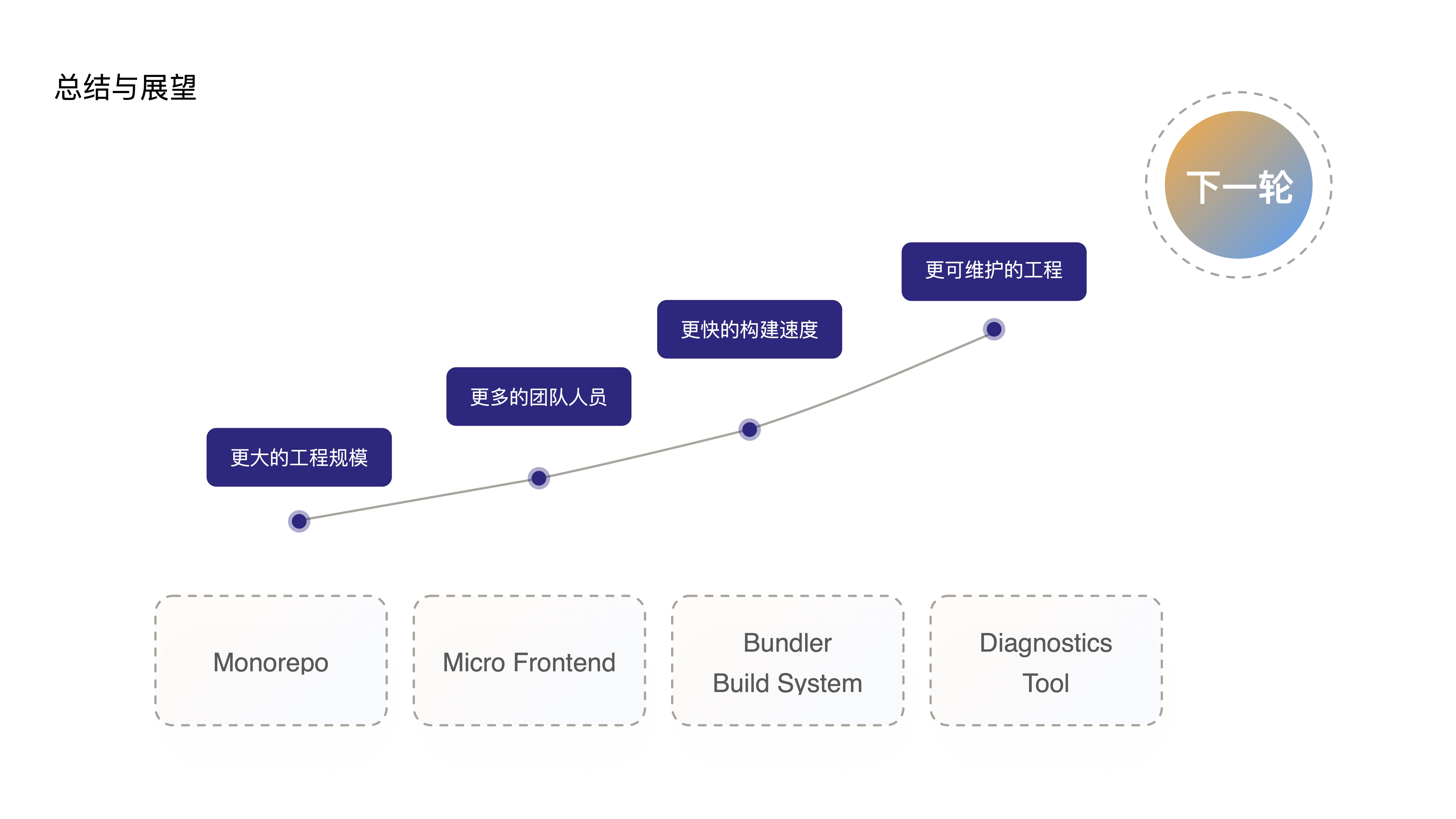
- 接下来做一个简单的总结和展望:
- 当上述一系列工具链支撑了更大的工程规模,更多的人员规模,更加快速的构建速度,更可维护的前端工程之后;
- 我相信未来一定会催生出更『强大』的前端应用,当这个更强大的前端应用继续增大工程规模,增加团队人员,渐渐地拉低了构建速度和可维护性
- 那未来必将会对这些工具提出更高的要求,从而带动整个前端工具链再一次革新

- 谢谢,这就是我今天带来的分享
PPT 附件
字节跳动的前端工程化实践

